
Introduction
The successful use of tagging systems on commercial Web properties such as Flickr.com and delicious.com has increasingly been followed by the adoption and implementation of tagging systems on various library and museum Web sites. Two excellent examples of this trend include LibraryThing (http://www.librarything.com/) and the Brooklyn Museum Collection Online (http://www.brooklynmuseum.org/research/digital-collections/). As users have become acclimated to such systems, there has been a growing body of research surrounding questions of accuracy, relevance, and retrieval related to tagging systems specifically and folksonomies more generally within the context of cultural-memory institutions like libraries and museums (Trant, 2009; Morrison, 2007). In addition, research projects such as the Steve.museum site (http://steve.museum/) have provided further insights and gathered valuable research data on the intersection of user-generated tags and traditional classification.
While it is ultimately beyond the scope of this paper to resolve whether an ontology based on a traditional classification system or a folksonomy is best suited for information retrieval (Shirky, 2005; Mann, 2008; Voss, 2007), a number of related issues directly impacted the direction that the New York Public Library (NYPL) ultimately chose to take. Through the lens of the library's Commons participation we can provide a more in-depth look at:
- some theoretical and historical underpinnings of traditional library and museum metadata
- some choices NYPL made in transforming structured subject headings into tags for use in the Commons project
- specific challenges that occurred in the implementation of this project
- whether the goal of introducing de-structured metadata into a tagging system ultimately met the library’s expectations
- some guidelines which may be helpful for institutions looking to engage in similar projects and suggested future directions.
Project Background
NYPL's digitized content presented on the Web site NYPL Digital Gallery (http://digitalgallery.nypl.org) represents over 700,000 images from across the library's collections, ranging over Medieval illuminated manuscripts, historical maps, vintage 19th- and 20th-century posters, rare prints, photographs, and much more. The Library of Congress (LOC) Flickr pilot of early 2008 clearly demonstrated an immense opportunity to expose in a fresh way the world's historical photography collections to a vast new audience on Flickr and beyond (Springer, Dulabahn, et al, 2008). And in a short amount of time after the LOC pilot launched, with the input of Flickr Commons staff, NYPL's Digital Experience Group began planning for potential collection uploads to The Commons.
One of NYPL's early goals was to showcase the variety that exists across its historical collections while interacting with new audiences, aligning with the oft-stated desire to "be where our users are". In an exciting time to be engaged in working with digital collections, new institutions were coming on board The Commons, new norms of interaction were arising from within the Flickr community itself, and spectacular historical cultural objects that had rarely been seen outside of specialized and research collections went on display. Much of the library's digitized collections, outside of the Google Books project, was within the public domain and could therefore be uploaded as digital items to the Flickr Commons.
The Commons also represented an opportunity to start fresh, bibliographically-speaking, or the library could choose to utilize parts of its pre-existing metadata when uploading items from collections that had some level of description currently stored in NYPL's databases. On December 17, 2008, NYPL launched its Commons presence with 1,300 images from across its collections, many of which contained "tagged" subject terms that had been parsed from pre-existing subject headings. Within the first month, the 806 subject terms the library had uploaded were more than doubled by Flickr users to 1,803 total tags. As will be discussed further in this paper, the process of getting to those 806 initial tags gave the library an opportunity to rethink how it might utilize its existing metadata and touched on a number of metadata issues that currently confront the larger digital community.
Structured Subject Headings: Built On A House of Cards?
Before we look more at the Flickr project, it is useful to discuss how our cataloguing heritage affects library classification and description. Early on-line catalogs converted library MARC records into searchable, electronic holdings information. It is important to note that MARC – "MAchine-Readable Cataloging" record – data itself evolved directly from an earlier era of card catalog description. The MARC data format was developed in the 1960s (Furrie, 2009) to allow the input of bibliographic data in LOC computers, but the legacy of the bibliographic card catalog format has gone largely unchanged, even as catalogs have migrated into enterprise-level relational database management systems (RDBMS).
This can be seen in the following illustration (Figure 1) where a three-level hierarchy is expressed within a single subject heading: "Elocution - - Study and teaching - - Texas."
A modern, normalized, relational database would likely not store this kind of faceted information within a single field value, but instead store each value – "Elocution," "Study and teaching," and "Texas" – separately while relating these items through primary and foreign key identifiers. The goal of such a system is to maintain both the ability to relate associated items and the flexibility of storing the data at its most granular level, so that these values may easily be revised or recombined at some later point with other tables and fields.
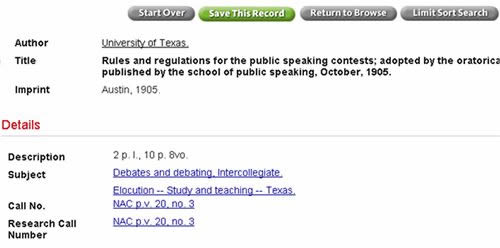
Fig 1: Card-catalog heritage in OPAC display
Shirky (2005) states that some of the tensions inherent in bibliographic classification in a digital setting may arise from a notion of a limited amount of shelf space. Although Shirky's analysis is applied to classification (call-numbers), not specifically to subject headings, the idea of limited concept space could be argued to also hold true for subjects: "a book which is equally about two things breaks the 'be in one place' requirement" (Shirky, 2005). Similarly, a catalog card held only a limited amount of description space, this being one possible constraint on the evolution of faceted subject headings, where many terms combine to contribute to an overall concept, one line at a time. Electronically, we have the space for more lines (headings), but the rules of headings themselves are bound to a world of card catalogs. It is exactly the power of relational databases combined with faceted indexing to expose connections, something that is exceedingly difficult to do in a top-down, pre-organized categorization scheme. Tags are well suited for – and arose, not insignificantly, in – such a database-driven environment.
In looking more closely at the first subject heading in Figure 1 again, if we were to break that heading apart, treating each element merely as data, "Debates and debating, Intercollegiate" could be expressed as "debates," "debating," and "intercollegiate”, essentially three "tags" that might reasonably appear within a larger folksonomy. NYPL's digital collections use a variety of controlled vocabularies in addition to the standard Library of Congress Subject Headings (LCSH), including Getty's Art & Architecture Thesaurus (AAT) and LOC's Thesaurus of Graphic Materials (TGM). But the specific schema matters less than the attempt of many subject schemes to supply laser precision in a single line versus casting a larger net. For example, the following LCSH subject found in NYPL's digital collections (see Figure 2), "Americans -- Employment -- New York (State) -- New York -- 1900-1909," maps to a hierarchy starting with country, and followed by working status, state, city, and era.

Fig 2: Americans -- Employment -- New York (State) -- New York -- 1900-1909. Digital ID: 805807
Additional qualifiers like "(State)" describe even more nested attributes for some of these terms. In database terms we would quickly want to store these separately, and let them combine where needed. If we look at just the punctuation here, we can see what appear to be a series of data delimiters: "—," ")," "(," "-". With the inclusion of commas, these delimiters map to established LCSH or AAT rules concerning the attributes and hierarchies in their relationships, much as a RDMS would do with related tables and fields. These values, as delimited data and converted to tags in the above heading, might also be expressed something like: Americans, employment, New York State, New York City, and 1900s, in no particular order.
Ontology: Classification or Description?
All of this leads us to a question: if subject headings have the potential to make even more searchable tags, then why are we still using them? One of the co-creators of the ISO Topic Maps standard, and an early pioneer of the Semantic Web, has described this a data projection problem, where our construction of organized, "top-down," conceptual hierarchies creates a number of roadblocks for successful information retrieval (Biezunski, 2007). Biezunski states that "the consideration of any piece of information either as data or metadata is a question of perspective ... and many data can be both." In practical terms, what this means for catalogers or users of tagging systems is that a "'top-down' approach emphasizes modeling uniformity ... defining models and persuading providers of information to understand them, and to make the information they provide conform to them" (Biezunski, 2007). We should ideally be making an effort to use "whatever information is available, and, with or without the provider’s cooperation, to try to make one or more kinds of sense out of it" (Biezunski, 2007). According to Biezunski's concept of "data projection" we have much to gain if we try to project multiple data dimensions into a two-dimensional space where we can filter by users' and creators’ perspectives.
This urge to allow the making of "one or more kinds of sense" was very much behind NYPL's exploration of merging structured metadata (librarian "sense") with unstructured tags (user "sense?"). And as we have done this merging, we have seen results that have overturned some of the expected paradigms. Users have become "experts," tagging Latin botanical classes for photos of algae; and catalogers have become "users" when subject headings are parsed into simpler terms like "tattoos," "farmers," "idols," "sleeping," "streets," "rocks," "rulers," and "statues."
Exposing Metadata as Tags
If bottom-up description can be said, in theory, to lead to improved information retrieval, NYPL additionally had other practical reasons for exposing metadata as tags. Had the choice to upload metadata only to the Flickr description field (and not as tags) been made, the data would still have been available for searching. However, one of the ongoing goals of the library's Digital Experience Group, now merged with NYPL's Strategic Planning office, has been to explicitly leverage staff expertise from across the library (Greenberg, 2009). For the library's growing digital presence across many platforms and data-streams, it is more critical than ever to utilize staff voices wherever they might emerge. Treating terms as linked tags acknowledges that catalogers, metadata specialists, curators, and others had spent much time and effort describing some items, something not to be deprecated for user-input nor privileged over user expertise. Rather than cloak or partition the subject headings, NYPL decided to upload them on the understanding that perhaps staff and users’ voices are not all that different.
There were additional concerns expressed whether introducing an “institutional voice” into the tags might have a chilling effect on user contributions compared with a “blank slate” approach. It is important to note that beyond The Commons, there are several Flickr tagging options already in place: users can lock out all tags other than their own, users can choose to tag and allow others to as well, or users don't have to tag at all. The LOC project staff had also observed that a "small group of 10 'power taggers' (defined as taggers who provided over 3,000 tags each)" had entered 40% (!) of all tags contributed in the first few months of the LOC pilot (Springer, Dulabahn et al, 2008). This led to the conclusion that if similar behaviours could be observed across other Commons collections, then it was not likely going to be easy to scare off such intrepid taggers with the addition of some library-provided terms. Furthermore, some collections like LOC's wonderful Bain News Service set (http://www.flickr.com/photos/library_of_congress/sets/72157603624867509/) were good examples of the power of user-contributions applied to a mainly undescribed collection. For NYPL, however, the larger concern was whether we could engage user contributions and activity in sets of digital items that contained a baseline of pre-existing, cataloged descriptions. Another factor that influenced our decision to upload subjects as tags was a mention by LOC staff that some users appeared to be copying and pasting into the tags field headings that LOC had uploaded to the description field (Springer and Michel, 2008). On the part of Flickr users, this seemed potentially to represent wasted effort that we might be able to help them avoid in order to focus on their own tags.
Parsing Traditional Subject Headings
NYPL's first attempt at uploading subjects was to simply load the complete headings, including punctuation, as Flickr tags. This resulted in a "tag-soup" where many headings that contained multiple terms were virtually illegible: for example, "basreliefsombosextinctcity." One early indicator that this first approach was not going to be tenable was the fact that for many of these tags, clicking the "see all public content" option in Flickr often yielded 0 results. Across Flickr's 200 million users and 6 billion photos, we would repeatedly find that not a single person had ever used our tags.
This led to further investigation into whether our pre-existing headings might be more easily transformed into something more closely resembling familiar tags. An earlier NYPL test project for the Digital Gallery which had parsed and de-duplicated subject terms into a browseable list of terms had yielded some success but had faltered under the sheer weight of our 58,000 subject headings: at that scale there seemed always to be between 2-5% of terms that remained outliers for the various pattern matches after parsing on heading punctuation. We were encouraged by how useful the results appeared to be when the parsing worked but had set the project aside for other work due to the above-mentioned issues of scale.
With arrival of the Flickr project, we were presented with another opportunity at a much smaller scale to see whether we could get better results on a more limited scope. With an initial upload of only 1,300, the fact that Flickr could also allow for some quality-control or post-processing to be easily applied within its CMS was an appealing option as well.
Our technical approach for this project focused on trying to ask "what is the simplest thing we could possibly do?" In the spirit of a beta project, every attempt was made to keep the overall process as simple as possible. A series of regular expression parsers that had already been written for the previous subject-terms project were applied to our pre-existing tags when the uploading scripts ran. We did not have to worry about de-duplicating multiple terms (e.g. "... New York (State) - - New York") because Flickr's internal batching process throws out any duplicate tags that are attempted for a single item. Flickr's API also supports the uploading of multiple combinations of exact phrase and single term tags simultaneously, making the tag-parsing script even easier to implement locally.
The regular expression match-and-replace scripts primarily focused on constructions like term1 -- term2 (term3) -- term4, where term might be a single word or a phrase. Some additional attempts were made to deal with commas in headings, but there is a great variety of comma-based parsing to account for when one looks at historical names and other place names. Transforming "Washington, George" is straightforward, but many historical names appear more like the following:
Anne Clifford Herbert Pembroke (Countess of)
Zinzendorf, Nicolaus Ludwig, Graf von, 1700-1760
Alexandra, Queen, consort of Edward VII, King of Great Britain, 1844-1925
Technically, every historical name in subject headings could be parsed into something like a display name suitable for tagging, but it would be beneficial, ironically, if this were part of a controlled vocabulary mapping in a cross-institution schema. Due to the limited ongoing scale of the project, we chose to handle outliers by generating tag-clouds for each set via Flickr's API, and then scanning those clouds individually. In this context, outliers jump out quickly and are trivial to change in Flickr's backend CMS. Since one change is addressed to every instance of that tag throughout an owner's photostream, this was a surprisingly efficient process to implement, and it took very little time to tweak tags like this after running the upload parsers. This is the approach we took to turning names into un-dated display names: thus "St. Denis, Ruth, 1880-1968" became the tag "Ruth St. Denis" through this tweaking process. Names represented a small minority of all subject headings, so this process was also relatively efficient, but in a large named collection, some type of algorithmic process would need to be applied, with the caveat that, as mentioned before, names are more difficult to parse.
Some Terminology Challenges
In addition to highly nested name structures, there were some other challenges in parsing subjects. These included the following:
- life-dates (excluded) and other date-ranges
- manual filing field punctuation ("Deer hunting -- Erie, Lake -- 1810-1819" versus "Erie, Lake, Battle of, 1813")
- "&" in concept mappings ("Good & evil" versus "Carts & wagons")
- archaic terminology ("Homes & haunts," "City & town life")
For life dates, we eliminated them from the tagged name versions. For dates covering a range ("1810-1819"), we parsed them into a tag "1810s." Due to complications in how Flickr handles historical decades for uploaded photos, we chose to not try to express ranges in Flickr's technical metadata as a "created date." We did, however, apply single dates, when available in our metadata, as a Dublin Core coverage/creation date as an embedded Flickr machine-tag. Our digital metadata <META NAME="dc.Coverage" CONTENT="ca. 1906"> becomes the Flickr machine-tag "dc:coverage=1906," for example.
For compound expressions, as McGrath (2007) states,
the compound or complex nature of many individual topical terms in LCSH, such as ‘Cookery, Indic’ and ‘Absurd (Philosophy) in literature’ causes difficulties for the development of clean, consistent faceted interfaces because the component parts cannot be manipulated individually.” (McGrath, 2007)
Breaking this down to parsed and transformed terms we might actually get something useful enough, though, since “Cookery, Indic” becomes “Indic Cookery” and “Absurd (Philosophy) in literature” could become a set of simpler terms: “Absurd,” “Philosophy,” and “literature” if the pattern "term1 (term2) in term3" were looked for.
Because of the difficulty in consistently approaching these kinds of terminology issues, we decided to treat most of these exception outliers as single edits in Flickr's backend systems rather than deriving a pattern for every single exception. Where possible, we chose to break apart most terms on the "&" and upload both unless it was part of a corporate name. Due to exceptions like "good & evil" we needed to do this post-processing on a case-by-case basis. With Flickr's robust API for metadata, it was relatively straightforward to both do this analysis and make revisions as needed.
In terms of actual processing, our regular expression code for all of the automatic transformations is relatively straightforward. All subjects are output to a single line separated by pipe ("|") delimiters. Then every "—" is replaced by a pipe delimiter. At the end of this process the result is a single row of terms (tags) delimited for uploading as separate tags for each digital item. Where two or more terms exist together, quotes are added to signal to Flickr that these are to be treated as phrases. A sample of the parsing code can be seen in Fig. 3.
ReReplace(Replace(arrTodaysSubject[i]," -- ","|","ALL"),"\(([^\)]*)\)","|\1","ALL"); |
Fig 3: Turning punctuation into tag delimiters
The goal, as in everything else, was to keep it as lightweight as possible. One of the few exceptions written in the parser code so far is the elimination of the floating "State" when "New York (State)" gets parsed to "New York" and "State." Feasibly other exceptions could be easily added if further analysis of terms highlighted syntax-based conversions that could be applied consistently and automatically for those exceptions.
Some Outcomes & Lessons Learned
Since our typical production workflow has very little overhead, we have been able to focus on the quality of the automatically-generated and revised tags. One of our biggest lessons learned is to be willing to delete outliers rather than contorting over how to parse these. Some traditional subject terms do not play well with tagged terms, so there is no point in pushing these into what is already a metadata surrogate for the pre-existing "real" metadata. This in no way affects the original metadata: only the terms that Commons users will be interacting with. We found, for example, that terms like "City & town life" at least in our collections predominately reflected city life, perhaps due to an era when towns and cities were more alike than they are today. So those tags are currently revised to "City life." Similarly, "Homes & haunts" has so far failed to reveal a single haunting; they all relate to pictures of homes. If a tag or combination of terms just does not fit in, we choose not to upload it. Flickr has over 200 million users who are also a valuable resource in determining the viability of any given tag. Simply clicking the "public content" link can often determine if a parsed tag is a candidate for exclusion.
We have also found that disambiguation may be over-rated. A variety of synonyms exist in traditional subjects, yet that is not usually pointed out as problematic. Yes, users can tag "horse" and "horses," but other clustering algorithms can be used to associate those terms, which Flickr in fact does. At the end of the day, we have found it most helpful in analyzing tags to be true to the image: if our parsed tag reflects a concept like "eating & drinking" while those depicted in an image are clearly only drinking, perhaps this tag could be revised.
We do a majority of our ongoing tag analysis on a Flickr test-account. Ideally one would use three accounts for this purpose: testing, staging and production. At Flickr’s current rate this would cost less than $100 per year to maintain. Using Flickr’s robust and open API to pull our uploaded tags in combination with Flickr’s on-line tag editing tools has proved invaluable in making subject outlier revisions as painless as possible. Turning the quoted terms “art and architecture” into two terms, for example, was as trivial as spotting "artandarchitecture" in a set-cloud generated by the API, and then clicking an edit-link in our interface to the Flickr CMS, and from there deleting the “and.”
It would be invaluable to also have access to a cross-institution collaborative parser, where exception pattern-matches on outliers, once made, could be used by all going forward in a kind of open-source metadata parsing project. One large hurdle to such an implementation could be that some institutions may consider their descriptive practice to be somewhat idiosyncratic and necessarily tied to local needs or curator preferences; however, in a corpus as large as Getty or LCSH headings, within a reasonably designed collaboration such local variances could be accounted for and even given back to the community as pattern-extensions, much the same way open source software can be modified or extended for local needs. There are some projects such as SKOS (Simple Knowledge Organization System) (http://www.w3.org/2004/02/skos/) that are moving in this direction, although not specifically targeted at tagging.
Finally, one of the largest questions going into this project was whether Flickr users would tag at all when items had been "seeded" a priori with some tags. Our evidence so far has shown that not only will they add tags, but also the variety of "taggified" subjects and user-generated tags is nothing short of astounding, especially in the context of how little effort it has taken to support. After NYPL's Commons collections went live, in the first month users had more than doubled the number of "original" tags. In the first year, the total tags have continued to grow to a current count of 3,059 tags. See Figures 4-7 for examples of before-and-after tagging activity within selected sets.

Fig 4: NYPL tags for Cyanotypes of British Algae by Anna Atkins

Fig 5: User-generated and NYPL tags for Cyanotypes of British Algae by Anna Atkins http://www.flickr.com/photos/nypl/sets/72157610898556889/

Fig 6: NYPL tags for Japan/Kimbei Kusakabe

Fig 7: User-generated and NYPL tags for Japan/Kimbei Kusakabe http://www.flickr.com/photos/nypl/sets/72157610971119088/
We have in fact observed that our collections which were “pre-tagged” have had more tagging activity than untagged collections. This could largely be due to the following factors:
- tag seeding does not inhibit taggers
- tag seeding allows for more discoverability in an ever-growing pool of Commons items
- exposure of a collection is more indicative of whether it will be tagged by users than whether it has been pre-tagged: views = tags
Conclusion
In conclusion, we have found that with very little overhead required beyond a willingness to engage in some basic pattern analysis, we have largely been successful in merging much of our existing structured metadata, in the form of structured subject headings, with user-generated tags. It is also becoming entirely possible to imagine a metadata universe where today’s user-generated tag will eventually integrate easily and conveniently alongside a description written a century ago. In the process of making this integration a reality, we have a golden opportunity give new life to historical images with institution-generated content exposed to new users and new contexts.
References
Biezunski, M. (2007). Reflections from Advancing Topic Maps: Maintenance of Concept Integrity as Names Change. Collaboration Expedition Workshop, #58, NSF, Arlington, Virginia. Last Updated: February 27, 2007. http://colab.cim3.net/file/work/Expedition_Workshop/2007-02-27_IdentityManagementExploration/biezunski_identity_20070227.ppt. Date accessed: January 31, 2010.
Furrie, B. (2009). “What is a MARC Record, and Why is it Important?” In Understanding MARC Bibliographic: Machine-Readable Cataloging, Eight Edition. Washington: Library of Congress. Last Updated: October 27, 2009. http://www.loc.gov/marc/umb/um01to06.html. Date Accessed: January 31, 2010.
Greenberg, J. (2009). Staff Expertise as Digital Strategy. DISH2009, Rotterdam, the Netherlands. December 10, 2009. Last updated: December 10, 2009. http://www.slideshare.net/DISH09/josh-greenberg. Date accessed: January 31, 2010.
Mann, T. (2008). On the Record but Off the Track, A Review of the Report of The Library of Congress Working Group on The Future of Bibliographic Control, With a Further Examination of Library of Congress Cataloging Tendencies. Last Updated: March 14, 2008. http://www.guild2910.org/WorkingGrpResponse2008.pdf. Accessed: January 31, 2010.
McGrath, K. (2007). “Facet-Based Search and Navigation With LCSH: Problems and Opportunities”. code4lib Journal, Issue 1. Last Updated: February 5, 2008. http://journal.code4lib.org/articles/23. Date accessed: January 31, 2010.
Morrison, J. (2007). “Why Are They Tagging, and Why Do We Want Them To?” Bulletin of the American Society for Information Science and Technology, October/November 2007, 12-15. Date accessed: January 31, 2010.
Shirky, C. (2005). Ontology is Overrated: Categories, Links, and Tags. Last Updated: January 25, 2006. http://shirky.com/writings/ontology_overrated.html. Date accessed: January 31, 2010.
Springer, M., B. Dulabahn, P. Michel, B. Natanson, D. Reser, D. Woodward, & H. Zinkham (2008). For the Common Good: The Library of Congress Flickr Project. Last Updated: December 09, 2008. http://www.loc.gov/rr/print/flickr_report_final.pdf. Date accessed: January 31, 2010.
Springer, M. & P. Michel (2008). "Common" Goals: The Library of Congress Flickr Pilot Project. Digital Library Federation Forum, Providence, RI. Last Updated: June 04, 2009. http://www.diglib.org/forums/fall2008/presentations/Springer.pdf. Date accessed: January 31, 2010.
Trant, J. (2009). “Tagging, Folksonomy and Art Museums: Early Experiments and Ongoing Research”. Journal of Digital Information, Volume 10, No. 1. Available at: http://journals.tdl.org/jodi/article/view/270. Date accessed: January 15, 2010.
Voss, J (2007). “Tagging, Folksonomy & Co - Renaissance of Manual Indexing?” In ISI 2007 Proceedings. Cologne, Germany: 10th international Symposium for Information Science. Last Updated: April 30, 2007. http://arxiv.org/abs/cs/0701072. Date accessed: January 31, 2010.