
Introduction
This paper, and the work behind it, starts with a Big Hairy Audacious Goal.
It’s not a new goal.
It’s not a particularly original goal.
It’s a goal that museums have striven for since they started distributing collections content on the Web.
The goal is this:
To provide cross-collection, cross-museum and cross-subject access to the biggest set of collections data possible, and to do this in a way which carries minimal inertia, minimal cost and minimal effort from all contributing institutions.
Furthermore, we believe that access should be provided via a simple, transparent and open API, to maximise re-use and innovation around our collections.
Hoard.it - as we’ll demonstrate in this paper - does not answer this BHAG. It does, however, take an existing set of assumptions and reassesses these in as realistic a light as possible.
Where academic commentators hold up RDF, the Semantic Web and "bottom-up" collaborative projects, we instead look to our Hairy Goal and ask: "what is realistic? What gives us the most impact for the minimum effort?" We take the realities we all understand in our institutions - little money, no time, high levels of inertia - and ask what we can do to overcome these, or at least side-step them in the short-to-medium term.
Hoard.it is not a perfect answer, as we’ll see below. It’s a technology which generalises, both with regard to the on-page templating system it uses, and also in the way we’ve had to normalise data. Many information professionals or curators will find this normalisation difficult to accept.
We suggest, however, that in a world where Google (a non-metadata-driven search engine) dominates, and museums are desperate to make their collections more "real" to younger, faster, more fickle audiences, that perfection really is the enemy of the good. Quantity, speed, openness - the ability to take our data and re-work it into other things: mobile applications, map mashups, timelines - these are what will ultimately define the impact of our collections on-line.
Existing Cross-Collections Projects
It is staggering to think how much time and money has been spent on largely comparable cross-collection projects globally (including similar projects, e.g. federated searching), and how this trend appears to be continuing despite the ever-growing number of existing projects.
A cursory search in Google reveals a variety of large-scale projects that have already launched: Cornucopia (http://www.cornucopia.org.uk/), Europeana (http://www.europeana.eu/), Michael (http://www.michael-culture.org), People’s Network (http://www.peoplesnetwork.gov.uk/discover/), Collections Australia Network (http://www.collectionsaustralia.net/), Virtual Museum Canada (http://www.virtualmuseum.ca), and many more. Between them, these have accounted for many tens - or possibly hundreds - of millions of dollars of investment, and an untold amount of time.
Even still, institutions continue to pour money and effort into yet more similar projects that provide centralised ‘portal’ access to cultural data: National Museums Online Learning Project (http://www.vam.ac.uk/about_va/online_learning/), BBC CenturyShare (http://tinyurl.com/centshare), and SPIRIT (Aberdeen University; no URL yet) are just some in the UK that we are aware of. Each of these is likely to cost hundreds of thousands or (in some cases) millions of dollars more.
Before we know it, we may have as many ‘one-stop-shop’ centralised portal sites as individual institutional sites.
Although we were unable to identify traffic or unique visitor statistics for these Web sites, it is highly likely that they attract a relatively small audience after their initial launch. Our opinion is that too much investment to-date has been spent on the obvious technical challenges of such projects (e.g. implementing OAI-PMH or OpenSearch at each participating institution), with very little innovation in end-user experience and how added value/context can be extracted and delivered through the newly formed aggregate data set.
The Problem
As a starting point, let’s examine the issues from the very highest level:
- Museums and cultural institutions around the world have collections data on millions of objects;
- There have been (and continue to be) large-scale moves to digitise at least some of these objects and put them on the Web;
- Ergo, there are currently hundreds of thousands of museum digital objects on-line;
- These objects are often related - between institutions - in some conceptual or semantic way. Well known artists, for example, may produce works which are distributed around maybe tens or even hundreds of museums worldwide.
Now let’s take a use-case. In this scenario, a user wants to know everything there is to know about Leonardo Da Vinci. She wants to see (for example) all the pictures, all the institutions that house Da Vinci material, a timeline of Da Vinci artwork from institutions worldwide.
Working on the assumption that this user doesn’t know which institutions to go to or the names of the artefacts she’s interested in (and bear in mind that most current projects fail here), the digitisation projects outlined above then become entirely reliant on effective search engine optimisation, given that this user is likely to go to Google first rather than to any of the contributing organisations.
Google doesn’t do this job well - try searching for "da vinci paintings" and note both the lack of structured results and the lack of coherent museum collections returned.
If Google can’t do this well, museum digitisation projects are destined to remain as niche silos, undiscovered by the audiences we’re so desperate to reach.
Cross-Collections Access
As museums have recognised for some time, the answer to this kind of problem lies in finding ways of gathering collections data into one place, harnessing the quantities of collections and attempting to capitalise on this for increased search engine optimisation and hence increased user access.
This kind of cross-searching is not an unrealistic user expectation, and yet it is held up as a holy grail in museum circles, for very real reasons that are clear to anyone working in the field of cultural heritage:
- We’d need a (worldwide) cross-museum agreed-upon standard for collections access
- We’d need to find the time and money to provide this data in a compatible format
- We’d need to overcome considerable organisational inertia and politics
None of this is news for anyone working with cultural collections. Time (as well as vast quantities of budget, as outlined above) has been spent on attempting to get these standards agreed and deliver "portal"-like access into the collections of small collaborations of museums. Most recently, for example, is the high-profile Europeana project which, according to ZDNet UK (http://news.zdnet.co.uk/itmanagement/0,1000000308,39460406,00.htm) is likely to have £120m allocated to it over the coming years.
The problem with these kinds of projects (even providing we’ve overcome the points outlined above!) is that because of their scale they are by definition inertia-ridden, expensive and slow-moving.
Consider this: There are 17,500 museums in the United States alone (http://www.aam-us.org/aboutmuseums/abc.cfm). A consortium of 5 museums (a standard sized cross-collections project group) therefore represents 0.02%. Extending this - a consortium of 500 museums (imagine the politics!) is under 3% of US museums.
Even if this consortium of museums could orchestrate a digitisation project, agree the standards, get the funding and launch, the output would still represent a tiny drop in the ocean when you consider our user looking for material on-line. The reality, of course, is that a consortium of 500 museums wouldn’t stand a chance of getting the representatives into a meeting room, let alone running any kind of coherent project.
To be very clear - this is not a criticism of the institutions or projects involved. The end results of existing digitisation projects are sometimes beautiful, and - once you have found them - sometimes reasonably satisfying. In the general scheme of things, however, they don’t - can’t - make use of the lightweight, rapid, agile approaches that define successful Web offerings today. They can’t provide the kind of true cross-collection searching that our fictional (and yet, highly probable) user requires. What’s more, very few of them have an API, so re-use is extremely limited.
There is a fundamental problem with the bottom-up basis upon which these projects are run. As well as being too expensive and cumbersome, they also ignore a huge issue: what about the existing projects? What about the hundreds of thousands of digitised objects from museums, large and small, already on the Web? Are these just lost projects, budgets spent and data ignored?
What we need is a solution that could in a matter of weeks rather than decades collect and provide access to object data from every museum in the world. This hypothetical ambition (our BHAG!) will not come from the bottom up in the form of large, sprawling and expensive collaborations. It will come from the top down, as recent history has shown in Internet development. This is the only way that we can ensure that our digitisation work has maximum impact, embraces the so-called "Network Effect" or Metcalf’s Law of network scale (http://en.wikipedia.org/wiki/Metcalfe's_law).
The Semantic Web, APIs and Programmatic Access
The idea of the Semantic Web - a common framework that allows data to be shared and reused across the Web - has been around for a number of years. Many advances have been made, not least the development of working groups, design principles and other technologies.
Theoretically, of course, the exposing of semantic data would solve many of the problems outlined above.
However, notions of the Semantic Web have been challenged by many commentators. While the "lightweight" Web has seen the evolution of, for example, RSS as a commonly accepted standard and REST-ful APIs as the means of sharing data between sites, RDF (the underpinning technology behind most formal Semantic Web systems) has lagged behind. There are very few sites (fewer still mainstream ones) which use RDF in any fundamental, semantic way.
It is very clear to the authors of this paper (and many other commentators) that for the near future at least these standards will remain as niche, academic notions of a perfect world of connected data, and not implemented in real world mainstream scenarios. RDF is too big, the benefits are too intangible, the chicken-and-egg of take-up is too small. Institutions, least of all cash-and time-poor cultural institutions, simply will not invest what is required.
Simplistically, the ‘second best’ option to the "capital S and W" of the Semantic Web is a Web where data can be accessed by machines as well as by humans. The connections aren’t intelligent in the way they should ultimately be with the Semantic Web, but this "connected Web" is nonetheless an incredibly powerful indicator of the shape of things to come.
On the Web, these technologies have gained a huge amount of traction, particularly around Application Programming Interfaces (API’s). They are one of the most important aspects of Web2.0 - an underlying interface layer which allows sites and services to query each other.
Why programmatic access is important
Perhaps the easiest way to explain this is to examine the current content and technology landscape outside the museum sector.
It is here - particularly among technology startup companies and other young, content-rich sites - that we see real, tangible evidence of the creativity and content exposure which springs directly from the exposure of machine-readable data.
Here are some examples, taken from Dion Hinchcliffe’s ZDNet blog (http://blogs.zdnet.com/Hinchcliffe/?p=215):
- eBay, who provide access to all their listings data via a feature-rich API, receive over 6 billion API calls per month. Over 60% of listings come from their API
- Twitter, whose API receives 10 times the traffic of their Web site. Their open API has allowed numerous applications, sites and services to access the power of the Twitter social graph
- The Flickr API, which provides the content for hundreds of mashups
- Other extremely high profile projects, including Google maps, the Yahoo! API, BBC Backstage
Hinchcliffe goes on:
Growth and innovation are both direct outcomes of APIs since it allows others to connect their audience to your products elsewhere on the Web (growth) and it allows products and services to be re-imagined and transformed into entire new products, services, and especially mashups, using ideas from across the network.
APIs power the world of the "mashup", where services and systems are brought to bear on common, otherwise complex problems. They also allow freeform building of creative tools on top of rich data, the embracing of the true power of "the network effect" and considerable advantages when it comes to future-proofing.
Sharing of Museum Data - the Landscape
Given these considerable cultural and financial advantages, the public exposing of data in programmatic ways is not common among museums and cultural institutions. Although there are no metrics around data provision of this kind, we believe that only a handful of museums worldwide are making use of these tools. Although RESTful approaches, for example, are deeply embedded in nearly every new Web2.0 startup, this is clearly not common ground for cultural institutions.
Some museums are making use of RSS feeds to expose data beyond simple event and news information - OpenSearch (http://www.opensearch.org/Home) is probably the most commonly used lightweight data-sharing mechanism. A few other institutions are running beta systems which use RDF or micro-formatting as a way of signposting granular content blocks within content pages. For the most part, however, this is not common practice.
Reasons for this lack of take-up vary. On the one hand, these are reasonably new approaches, especially in a sector that has never been rich enough or inclined to be "bleeding edge". On the other, museums still have a tendency to be cautious when it comes to exposure of raw data into the public domain. Finally, of course, there are matters of data standards and - not least - the communication of why data sharing is important.
There is an obvious chicken-and-egg scenario here: until more museums commit to exposing their data in these ways, metrics will not be available; until metrics are available, museums are unwilling to commit.
Hoard.it: The Top-Down Approach
With hoard.it, we took a completely new, completely realistic approach to collections searching. We started with several core principles:
- The Web as it is today contains many hundreds of thousands of (cultural) resources
- These resources are valuable, but there is little/no consistency in the way they are presented.
- There is absolutely no guarantee that...
- these resources are marked up semantically
- there are programmatic ways to get at the underlying data
- the markup is valid or otherwise "correct"
- there are any standards at all being employed consistently
4. The system should allow for the fact that these resources may become better represented on-line in the future via Semantic Web technologies, microformats, API’s and so on. The system should not in any way preclude development in these directions.
With these in mind, we set about designing a system which followed these principles:
- We should be able to rapidly gather data from a variety of (museum) data sources using the "visible" Web - i.e. Web pages
- The system should provide a powerful API to ensure the maximum possible re-use of any data collected
- The system should demonstrate the value of aggregated collections data in a way that no system has previously
- The system should be agile and lightweight by...
- not requiring any changes to be made to the source sites or the markup on those sites
- not requiring any consent from the source sites
Technology Overview
As one of the main goals of the project is to demonstrate that other ‘formal’ projects are over-engineered - and hence overly resource intensive - our system is built using simple technologies, with just enough functionality to achieve simple tasks, and no more. It is essentially a non-robust proof of concept, but one that attempts to match or exceed the results of many other larger projects.
A configuration file is created for each Web site, one that defines how to crawl the Web site and where relevant data can be found on the page. Each Web site is crawled, and a rudimentary screen-scraping engine used to extract the data from each page. As only a single configuration file is defined per site, it is assumed that the ‘data fields’ exist in the same position on each page; i.e. that all pages on the site are built using a consistent template.
The main platform is built with open source technologies: Linux, Apache, MySQL and PHP; often referred to as LAMP. The core component is a simple PHP spider, which uses the inbuilt cURL library to spider each target site. A site is scanned for other valid pages to spider (e.g. collections database search results), and any valid URLs that could contain data (e.g. a page that displays a museum object or work of art); patterns that define the structure of valid URLs are specified in the configuration file for each site.
A second simple spider then crawls each data page. The page is downloaded, and normalized: converted to valid XHTML/XML using HTML Tidy, all URLs made absolute (i.e. changing relative URLs so that they contain the full address), and converted to a common character encoding (UTF-8).
The page is then parsed to extract the individual data fields; e.g. for an object, these could include attributes such as name, date, location, description and dimensions. In the configuration file for the site, a variety of different patterns can be used to identify the fields: metadata tags, xPath expressions, regular expressions and CSS selectors.
Once the data is extracted from the page, it is stored in a central database alongside a common label for the field - usually Dublin Core style labels, such as ‘title’, ‘description’, ‘identifier’, ‘date created’, etc. This ensures that data from all Web sites can be mapped and compared.
The Data
To date, we have collected data from 17 Web sites. This includes 68,000+ objects from 12 museum Web sites and 2 art galleries, 4,000+ museum details from 24 Hour Museum, 1,500+ artist details from Wikipedia, and 1,200+ historical events from Freebase. Of the museums, nine were from the UK, three from North America and two from Australia. We would like to include more non-UK museums/galleries in the dataset, but unfortunately the technical suitability - for screen scraping - of on-line collections seems to be higher in the UK than elsewhere, for Web sites we have tested to-date.
For the purpose of this project - and for the sake of expediency - we chose to collect a selection of data from each museum Web site, rather than each collection in its entirety. On average, about 5,000 objects were spidered from each Web site.
For each object, we collected a set of core fields: URL, identifier (unique ID), title (name), and description. Where possible, we collected other useful data, including image, creator, dates, copyright, dimensions, subject, location and materials.
About 50% of objects had creator information, 75% included date (created) information, slightly under 50% specified copyright information, 65% subject, 85% an image, 45% a location, and 65% a list of materials.
Mark-up and links were removed from all text, and other related information (including any other images or multimedia) ignored.
Difficulties and Limitations
As this project has no pre-arranged agreements with data providers, and no ability to alter the format or availability of data, there are a number of difficulties associated with our approach:
- A provider’s collection must already be digitised and publically available on-line
- Performance is not optimal: screen scraping relies on downloading the entire page - rather than just object data - and system throughput is limited by the response speed of the Web site; we had to discount some museums from our dataset due to poor response times.
-
A Web site must use a template for presenting
each object page, such that the various data fields are marked-up or located in
a consistent style across pages.
- There are still a surprising number of on-line collections that do not use any kind of semantic mark-up for their collections. From our research, art galleries seem to be the worst offenders, often concatenating a large number of separate fields (title, artist, date, copyright) into a single plain-text paragraph.
- Over longer periods of time, changes to Web site templates will prevent the screen-scraper from detecting changes or new data until the configuration for the site has been updated.
- There is significant variety in how each Web site adheres to standards, document type, character encoding, use of HTML entities, etc.
- As the prototype spider is fairly rudimentary,
it currently only crawls pages that it can find in the HTML of a page.
Therefore, pages that are only accessible by ‘Post’-ing a form or through a
JavaScript action are ‘invisible’ to the spider. Considering that many search
engine spiders could face similar barriers, it is surprising how many large
institutions implement these technologies, potentially blocking large sections
- possibly all - of their collections from search engine users.
- Similarly, images and data hidden inside Flash applications (such as Zoomify) are invisible to the spider.
Normalization
The most interesting difficulty - which also applies to the majority of other formal aggregation projects - is that of ‘normalization’; converting incoming data from different sources into the same units and format, so that it can be easily compared and mapped.
We normalized two of the incoming data fields: location and date. For location, we used the Yahoo! GeoPlanet API (http://developer.yahoo.com/geo/), which can convert most textual descriptions of places (cities, countries, landmarks, postal codes, etc.) into longitude, latitude and a single standard geographic taxonomy (country, administrative region, city).
We developed our own API for normalizing dates (http://feeds.boxuk.com/convert/date/), which converted approximately 95% of all incoming date formats we recorded (e.g. ‘circa 19th century’, ‘1960s’, ‘2008-01’, ‘1 Jan 52’, ‘2000 BC’), although some fuzziness exists where international differences cannot be calculated (e.g. 04-05-78; the order of the day and month are not certain). From the relatively small selection of Web sites we included in our survey, we detected nearly 50 different formats for specifying date information.
Although normalization of the ‘subject’ (keywords) has not yet been attempted, a service such as the Calais API (http://www.opencalais.com/calaisAPI) could be used to map disparate objects and taxonomies to a common vocabulary.
Data Analysis/Mining
Location
As perhaps is inevitable from the geography of the museums included in the survey, nearly 20% of the objects recorded originate from the United Kingdom (cf. 65% of the museums in the survey are located in the UK), with only 14% originating from North America (cf. 20% of the museums in the survey) and 2% from Australia (cf. 15% of the museums in the survey).
The figures are even more stark when viewed by continent: 65% of objects originate from Europe, 15% from Asia, 14% from North America, just over 4% from Oceania, just under 2% from Africa, and a very small amount from South America.
Although we do not currently include enough non-European museums to provide particularly significant results, it is also interesting to examine similar statistics based on location of museum. European museums are sometimes accused of being Euro-centric, so it’s surprising to find that although about 75% of objects from European museums do originate from Europe, and only 65% of objects are ‘local’ in Oceania museums, North American museums appear to be the least ‘global’ of our survey with approximately 85% of their museum objects originating from North America.
Date
From the museums and galleries included, there is a strong leaning towards modern history: 25% of all objects are from the 20th Century, and another 22% are from the 19th Century. In fact, 70% of objects are from the last 500 years, even though the records in the database cover a range of over 4000 years.
If we examine how museums from different locations collect objects by date, then we see a fairly predictable trend: European museums have a larger percentage of their collection dedicated to older objects, whereas North American - and particularly Oceanic - museums contain a larger proportion of modern objects, focused around the 20th Century.
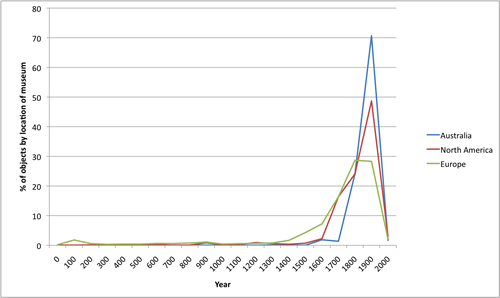
Fig 1: Date of objects by location of collecting museum
We can also examine how the date and the location of origin of each object are related. For African and South American objects, a larger than average number of the items from these regions are dated to Before the Common Era. Asian and African objects have slightly more of their collection dated to the Middle Ages.
Most continents clearly have the majority of their collection from the last few hundred years, with nearly 85% of Oceanic objects dated after 1900, over 70% of North American objects after the same date, and - perhaps surprisingly considering the long history of such a region - nearly 50% of all South American objects in our survey being made after 1900.

Fig. 2: Date of objects by location of object creation
If we examine how material usage changes over time, we find that a greater proportion (than average) of clay and stone items are dated from the Middle Ages (5th-16th Century), and a far larger than average amount of the silver and gold collection dates to the Renaissance period (14th-17th Century).

Fig. 3: Date of objects by material
As we are able to collect and map non-object data in our survey too - museums, painters and historical events - we can also begin to provide enhanced context for objects. For example, we can extract all objects made in Germany during World War II: this results in 19 objects, including toys and navigational globes. Note that many more objects probably should be included in this selection, but the Web sites we spidered did not publish location or creation date information on the object page.
Similarly, we can easily extract the eight objects in our collection that were made in Florence during Leonardo da Vinci’s childhood (age 5-15); these include five plaster cast statues, two oil paintings and a figurine, made respectively by Mino da Fiesole, Apollonio di Giovanni, Andrea della Robbia and Luca della Robbia.
"Hoard.it labs"
We are continually adding to the various ways of mining and displaying hoard.it data. See http://hoard.it/labs for examples, including timeline, mobile version, object quiz, etc.
Legalities
We have - as the title of our paper indicates - taken a "just do it" attitude to the hoard.it project. No consent has been requested from the museums which have been spidered; however, we have mentioned the project to many museum colleagues and they have all been supportive of the approach.
We believe that provided we continue to give end users a link through to the originating object record (i.e. to the museum Web site itself), we will not in any way adversely affect either traffic to the museum site nor any aspect of the individual museum brand. In fact, ultimately we believe that this kind of approach will drive traffic to and between museum Web sites extremely effectively.
In a world where Google, Google Images and the Internet Archive (to name but a few) contain spidered content from millions of sites, including our own, we consider hoard.it to be a drop in the ocean. We are aware, however, that museums may not wish to be spidered for whatever reason and provide an "opt out" option on the hoard.it Web site.
Next Steps
We have a number of ideas on our roadmap for hoard.it development:
Continued expansion
First and foremost, we intend to continue expanding the hoard.it database with more object records, more museums and more collections types.
Template Mapping
The most obvious of these is looking at ways in which we can improve the way in which the system maps page structure to content. As mentioned above, this is currently carried out using a simple configuration file for each template type. This makes several assumptions about the site which are not necessarily correct.
Building in further flexibility in the way this mapping relationship is defined is therefore a key part of fine-tuning the hoard.it spidering process. We are working on several ideas whereby this mapping could be defined not on the hoard.it side of the process tree but instead by the site owners themselves.
The obvious way of doing this would be allow site owners to define a <rel> link in the HEAD of their object pages which pointed to an external file hosted on the same site as the object pages. This file would contain a simple mapping language based on mapping the DOM to an easy to understand language (possibly even a variation of CSS). This would relate the on-page content to a pre-defined normalised field.
So for example, if the page contained the object name in the first <h1> tag on the page and a description in the second paragraph, the language might look like this:
h1[1] > dc.title
p[2] > dc.description
The hoard.it spider would be automatically configured to look for this particular <rel> tag, follow the URI and from there determine how the template page was mapped. The spider would (as now) be able to continue gathering page content based on other mappings should it not find this <rel> tag. Rather more interestingly, you could potentially crowdsource the definition mappings, allowing site users to do the work of mapping the relationships, or have a whole range of different mappings for different audiences or systems.
There is some ongoing work which is similar to this, in particular RDFa (http://www.w3.org/TR/xhtml-rdfa-primer/) and RDF-EASE (http://buzzword.org.uk/2008/rdf-ease/spec). These, however, require well-formed X(HT)ML on the input side and some fairly serious changes to existing markup, thus, in our opinions, removing the appeal we believe there is in a lightweight approach.
Microformats and <META> tags
Some work has already been done on Microformats (http://microformats.org/) for museum objects (http://www.google.com/search?q=museum+microformat), and there is a continuing debate about whether this is a worthwhile route for museums to explore.
Hoard.it could certainly easily be configured to look for specific microformats (whether object, event or otherwise) or metadata in the <head> of the page (see above): <head> data has been used on a number of sites (notably NOF digitise) and certainly is more abundant currently than any other method of representing metadata on-page.
The easy configurability of hoard.it means that as trends come and go, we can adjust the mapping algorithm (or let the site owner adjust it!) as required.
Other ideas, APIs and contextual linking
Once the core data from a page has been mapped and successfully imported into the hoard.it system, it is exposed as a RESTful API to anyone who wants to consume it. This of course means that rendering the object content into any format becomes trivial: text only, mobile, kiosk-friendly, large print, etc.
One idea we are working on is an embeddable "widget" which any museum could include by pasting a line of JavaScript code into a Web page. This widget would take the current page URI, map this to hoard.it and return a "you may also like" list of object records, either from the same domain or from the entire hoard.it database.
In the same way, exposing an on-page link to "view this page as XML" (or RSS, or potentially RDF) becomes trivial.
Conclusions
The hoard.it prototype system we have developed is a lightweight alternative approach to the typical resource-intensive cross-collections aggregation project, though it is not necessarily as accurate. However, because it is easy, fast and cheap to set up, it can run alongside the larger scale projects and developments; it doesn’t necessarily replace them.
As the system is not ‘object data specific’, it is capable of including any type of structured data into the same central database (such as people, events, and buildings), allowing us to eventually provide the end-user with far greater context around their particular area of research.
This mapping of arbitrary data sets to one another provides a straightforward method for ‘bootstrapping’ the Semantic Web; building up an ever-growing set of interconnected data objects, but without any technical changes to participating systems or knowledge of Semantic Web technologies.
Above all, we believe that the museum community should consider this type of ‘top down’ approach to the complex problems it faces: creating small, cheap systems that fulfil ‘just enough’ requirements and can be used on a large scale.
Appendix and References
1. Big Hairy Audacious Goal (BHAG) - http://en.wikipedia.org/wiki/Big_Hairy_Audacious_Goal
2. http://news.zdnet.co.uk/itmanagement/0,1000000308,39460406,00.htm
3. http://www.cornucopia.org.uk/
5. http://www.michael-culture.org
6. http://www.peoplesnetwork.gov.uk/discover
7. http://www.collectionsaustralia.net
8. http://www.virtualmuseum.ca
9. http://www.vam.ac.uk/about_va/online_learning
10. http://tinyurl.com/centshare
11. http://news.zdnet.co.uk/itmanagement/0,1000000308,39460406,00.htm
12. http://www.aam-us.org/aboutmuseums/abc.cfm
13. http://en.wikipedia.org/wiki/Metcalfe's_law
14. http://blogs.zdnet.com/Hinchcliffe/?p=215
15. http://developer.yahoo.com/geo
16. http://www.opencalais.com/calaisAPI
17. http://www.w3.org/TR/xhtml-rdfa-primer