Hernán Astudillo, Pablo Inostroza, and Claudia López, Universidad Técnica Federico Santa María, Chile
Abstract
Museums and archives have the goal of making available cultural heritage knowledge to more users. To reach this objective, it is a key challenge to integrate the information spread across many institutions. This information is related to cultural artifacts which bear witness to some circumstances relevant to a context: political, historical, social, etc. An integrated view of these common circumstances would give the final users a unique and rich experience. CONTEXTA/SR is a platform that takes advantage of the information resident in heterogeneous and distributed repositories of cultural heritage to enrich a common image of the world. This platform, based on Semantic Web technologies, is guided by some basic principles: extensibility, to allow new developments over a set of provided capabilities; progressive enrichment of original data through a series of transformations that use the Web as a source of information; and consideration of the final user as an information enrichment agent.
Keywords: digital repositories, semantic Web, integration, context, linked data
Cultural Repositories: How To Integrate Circumstances?
Archives and museums record information about artifacts that bear witness to a political, historical or social context. This information from several institutions is inherently interlaced by the mentioned context, although these links are not explicit because of institutional barriers.
Often, people who visit on-line museums and archives are more interested in the circumstances that artifacts are witness to, than in the artifacts themselves. Then, queries requesting “pictures of Victoria Square at González Videla’s government,” referring to the context of artifacts, become more valuable.
With the rise of Information Technologies, cultural institutions have started to digitalize the artifacts they keep, saving a digital representation of artifacts and also some metadata that describe their context. However, the fact that each institution uses its own technology and tools to manage the information makes inter-institutional contextualization a persistent problem.
There have been varied efforts to integrate heterogeneous heritage repositories. A naïve approach consists in a syntactic search engine that allows the search of keywords in the aggregated set of artifacts’ descriptions.
In this article the CONTEXTA/SR platform is introduced. Its goal is to provide unified access to heritage digital repositories, boosting the circumstances in which the digital artifacts are immersed.
The structure of this paper is as follows. The second section will introduce a case study that will act as a reference for the examples given throughout this article. The third section will expose the technological background and other projects that try to solve the presented problem using similar technologies to ours. The fourth section will present the CONTEXTA/SR platform and the key principles that guide its architecture. The fifth section will briefly describe the main repositories and components of the architecture. The sixth section will expose the platform as the nucleus of a software ecosystem. The next to last section will describe the processes of ingesting and auditing artifacts and their circumstances. Finally, the last section will present some conclusions and discussions.
Example for Discussion
To anchor our discussion and examples, we present a typical record (shown in Table 1) taken from the Margot Loyola Fund for Traditional Culture and Music (FML).
| Unit of information | MLP/CR03-03 |
|---|---|
| Document type | SM |
| Title | El Clavel |
| Singer | Chávez, Juanita |
| Documenter | Loyola, Margot |
| Country of Publication | Chile |
| Place of the event | Linares |
| Thematic descriptors | Traspuesta, cueca, guitarra, fiestas |
| Byte size | 3208345 |
| MIME type | audio/mpeg |
Table 1: Typical register from Margot Loyola Fund
Technological Background and Related Work
The case study shows that in the cultural heritage domain it is very relevant to consider the circumstances of artifacts when answering interesting queries. A common strategy used to discuss a concept without ambiguities is to give it a unique identifier. Then, if the individual “Margot Loyola” has a unique ID, it would be possible to refer to her from anywhere without confusion.
The infrastructure used to assign unique identifiers at a World scale exists: it is the Web. In the Web, each resource is identified by a unique global identifier known as a URI (Uniform Resource Identifier). In the past years, this technological infrastructure has been considered as the enabler to describe relationships not just between digital documents, but also between concepts that do not necessarily have a digital representation. This is the key idea behind Semantic Web.
The Semantic Web (Berners-Lee, 2001) is an initiative not only to use the Web as a medium to human consumption, but also to allow computer interactions. The more sites that make available their data in a machine understandable format, the more interesting the Web applications become. These applications benefit by the distributed and aggregated data.
The key technological support to do this is the RDF data model. This model considers as an atom of information, a statement that contains a source node, a property arc and a target node. At least the first two must be identified by URIs.
The Semantic Web vision also relies on artificial intelligence knowledge formalizations known as ontologies. An ontology is a specification of a conceptualization (Gruber, 1993). It can be viewed as a conceptual model that has logic formalizations which rigorously describe the world. However, heavyweight constructs of ontologies that enable complex inferences are not very helpful when there are high volumes of data dispersed across many geographical locations.
In the last years, the Semantic Web is mainly considered as the “glue” to integrate heterogeneous data across the Web using the following metaphor: concepts of the real world - which may have or may not have digital representation - have URIs. It is possible to create a network of concepts through the Web using “semantic properties” which also have URIs. This simple but powerful model, also known as the Web of Data, allows us to use the Web not just as a set of documents interrelated through hyperlinks, but also as a semantic network of concepts.
DBpedia project (Auer, 2007; http://dbpedia.org/) demonstrates the power behind the Web of Data approach. In this project, the structured metadata that it is possible to extract from Wikipedia articles is consolidated in an RDF data store. It can even be integrated with other sources of RDF on the Web, such as Geonames, DBLP and others. Moreover, in Dbpedia, URIs are provided for the concepts that Wikipedia articles describe: these concepts have semantic relations to concepts also identified by URIs. These uniquely identified concepts can be referred to from any chunk of data, in the same way that we can refer to any Web page from any Web page. DBpedia follows principles of Linked Data initiative (http://www4.wiwiss.fu-berlin.de/bizer/pub/LinkedDataTutorial/), whose goal is to publish RDF data on the Web and to interlink data between different sources of information.
In the context of cultural heritage, there are some interesting projects that use Semantic Web technologies. MuseumFinland (Hyvönen, 2005; http://www.museosuomi.fi/) is a semantic portal for publishing heterogeneous collections. It makes extensive use of Semantic Web technologies. One of the main contributions of this work was the idea of differentiating the syntactic interoperability from the semantic interoperability. Unfortunately, MuseumFinland does not expose the knowledge it integrates in a “dereferenceable way”. Thus, although it uses Semantic Web constructs, the concepts and artifacts it describes are not browsable or searchable in the Linked Data sense. The same group has recently made interesting contributions on how to model relevant content of cultural heritage using events and situations (Junnila, 2007; http://nsdl.org/).
The National Science Digital Library (NSDL) (Lagoze, 2005) has considered Semantic Web techniques to expose rich relationships among the artifacts they keep. It bases its platform on FEDORA, a digital object repository. FEDORA allows the associating of RDF metadata to each digital object it keeps. Moreover, the RDF data is indexed in a dedicated data store, and these statements are accessible through a provided component. However, this approach considers digital objects as first class entities. For this reason, any update to the RDF graph of relationships has to be done through the digital object API, with the overhead that this implies.
The Architecture of CONTEXTA/SR
CONTEXTA/SR is a platform whose goal is to semantically integrate cultural heritage heterogeneous information, using Semantic Web Technologies. To achieve this, there is a series of phases that we consider:
- Integration at a technological level: generally, each museum or archive uses its own technology and tools to manage its information. In this phase, it is necessary to execute a process that exports the original data into a technologically compatible format.
- Integration at a semantic level: even if the previous step was successfully made, it is possible that the contents of each original institution still remain isolated. Then, the more important step when integrating is to achieve semantic interoperability. In this phase, it is necessary to agree on a common vocabulary and map original constructs to it.
- Integration at a social level: once information is semantically integrated, it is the final user who could enrich it, as in the case of successful social Web applications such as last.fm, del.icio.us, flickr, among others.
There are some basic principles we have defined in order to achieve the integration at the three above-mentioned levels. These principles guided the definition of the architecture of the platform:
- Center on provision of services more than on particular applications
- Define circumstances of digital artifacts as first class entities
- Consider the user as an agent of information enrichment
- Use standard and not proprietary formats
- Give importance to auditing the integrated contents
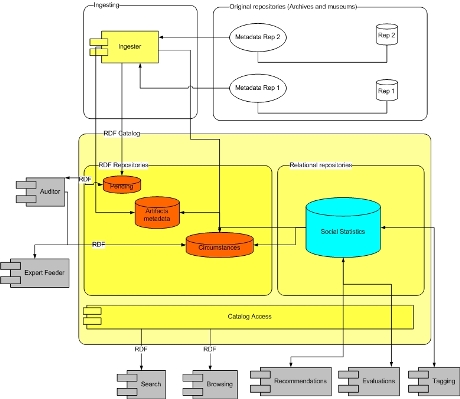
Fig 1: The architecture of CONTEXTA/SR
Figure 1 shows a high level view of CONTEXTA/SR architecture. The main blocks are:
- Source repositories with digital representations and their metadata.
- RDF Catalog internally divided into several repositories, each of them for a particular task. This catalog could be viewed as a semantic graph, having some nodes out of the catalog control.
- Main auxiliary components: these are dedicated to specific functionalities. Some of the components of primary relevance are the Ingester, the Auditor and the Expert Feeder.
First we describe the primary repositories of the RDF catalog and the ontologies that we use to model the information stored there. Then we briefly describe the components that achieve the integration of distributed resources.
The RDF Catalog
How We Model Artifacts And Their Circumstances
Using Semantic Web technologies in CONTEXTA/SR implies that almost everything is a resource. This means both digital representations of artifacts distributed across the cultural institutions and the circumstances they witness are resources. Then, we deliberately concentrate our modeling efforts in three dimensions: ontologies to describe artifacts, ontologies to describe circumstances, and social ontologies.
- Ontologies for digital artifacts.These describe low-level features of digital documents, such as byte size and MIME type. In figure 2 it is possible to see the case study example represented using a simple ontology of artifacts.
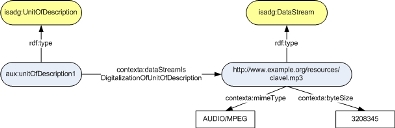
Fig 2: Example of a unit of information that uses concepts from an ontology of artifacts
- Ontologies for circumstances.These ontologies are related to the circumstances of an artifact. For this reason, the greater modeling efforts are related to these. There are efforts to develop a unified model for representing digital artifacts and their circumstances. CIDOC/CRM (http://cidoc.ics.forth.gr/) is an ontology that we considered, but we did not choose it because its hierarchy of classes was very complex. Also, it is not linked with widespread ontologies such as FOAF (http://www.xmlns.com/foaf/spec/), W3C Geo Ontology (http://www.w3.org/2003/01/geo/), the Music Ontology (http://musicontology.com/) or the Event Ontology (http://motools.sourceforge.net/event/event.html). We based our main ontology on the ISAD(G) (General International Standard Archival Description) standard (ISAD(G), 2000), which describes how to prepare archival descriptions. An ontology based on ISAD(G) constructs was combined with several widespread ontologies, such as Music Ontology, W3C Geographic Ontology, FOAF Ontology and others. ISAD(G) is a very detailed ontology specialized for the heritage domain. Also, it is possible to consider it as the glue between the other lightweight ontologies. The widespread ontologies we use allow us to reuse the knowledge of experts in each particular domain. Figure 3 shows the case study with concepts from ISAD(G) and other ontologies used to model circumstances.
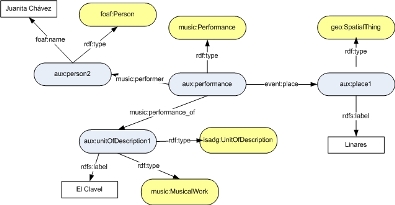
Fig 3: Example of a unit of information that use concepts from ontologies of circumstances
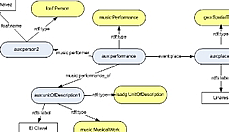
- Social ontologies:These ontologies model the context of the use of the artifacts and their circumstances. Some of the selected ontologies are FOAF for descriptions of persons and the Tag ontology for tags managing. Figure 4 shows the case study enriched with social information.
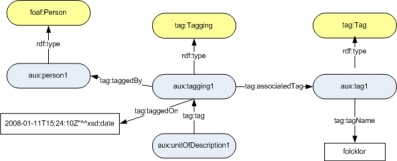
Fig 4: Example of a unit of information that use concepts from social ontologies
The Repositories
We have explained how the data was modeled; it is possible to describe briefly the repositories where the instances are stored.
- Repository of artifacts metadata.This repository stores the low level properties of the digital representation of an artifact. It is in this repository that the byte size or MIME type properties of a digital document are registered.
- Repository of circumstances.The relations between the digital representation of an artifact, the artifact itself, and its circumstances are stored in this repository. In this data store the URIs for “Margot Loyola”, “Talca”, “El Clavel” (song) and their relations are stored.
- Pending repository.The data that has been ingested but not yet audited is stored in this repository, while waiting to be integrated to the circumstances repository. The role of this repository will be better explained in the next section related to the ingesting and auditing processes.
- Repositories of statistics of use.This repository registers the use statistics to provide the recommendation services which enrich the final user’s experience. Unlike previous repositories, this one is relational. This is to facilitate the development of algorithms and calculations needed to compute recommendations.
Above all these repositories, there is an abstraction layer called “catalog access”. This is implemented as a component that allows treating all the underneath data as a unique integrated RDF graph. It provides capabilities for executing SPARQL queries and performing semantic browsing through all the stored resources: digital artifacts, circumstances and social information.
The Main Components
As Figure 1 shows, there is a series of components above the RDF catalog. These components are fundamental for integrating the distributed repositories. In these components, the logic needed in order to achieve the semantic integration is embedded. Next, the more important components are briefly described:
- Ingester. This component generates RDF chunks of information from the particular data of an institution. It takes as input the XML files that contain the serialized data from the source repositories and produces as output an RDF graph connected with the already-stored circumstances.
- Auditor. This component provides capabilities for approving the data stored in the pending repository and transferring the information to the circumstances repository. Also, it has features for rejecting some invalid data.
- Expert feeder.This component provides capabilities for directly feeding the circumstances repository, without using the ingesting process.
- Social components.The users, recommendations, tagging and evaluation components provide capabilities for accessing users’ profiles and the statistical information about the use that these users give to the data. This kind of information may complement the semantic information that is already stored with emergent social knowledge. In this paper, we do not deeply discuss this topic that is significant on its own. In the work of steve.museum (Wyman, et al., 2006) it is possible to see the potential of considering social information in the cultural heritage domain.
The Ingesting and Auditing Processes
In Figure 5 it is possible to see the workflow of the ingesting process.
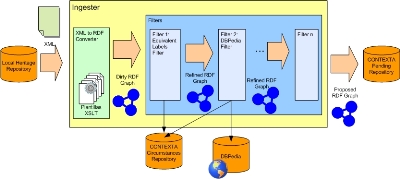
Fig 5: Workflow of the ingesting process
First there is an XML chunk of information exported from the database of a local institution. We assumed that local repositories have a method to export to XML as a precondition at a syntactic integration level. This is true in almost all current databases.
Once the XML file enters the ingester component it is necessary to convert it into an RDF representation. In reference to the common ontologies described above, the vocabularies become semantically uniform. This is possible because the Ingester has a set of XSLT templates, one for each admitted data format. In other words, for each repository that wants to be integrated to CONTEXTA/SR, there has to be an XSLT template that transforms the data from its local format to the common vocabulary. The development of this XSLT template is a hard task that consists in mapping the original source constructs to the ontological constructs introduced previously. This task requires a great deal of human effort for successful integration.
Once the transformation to RDF is realized, a graph is produced. This graph is totally disconnected from the circumstances registered in the platform repositories, and hence, to the world. In order to link the nodes in the output graph to existing nodes on the CONTEXTA/SR semantic repository, or even to nodes on the global Semantic Web, filtering stages are necessary. In this process each stage produces a more refined and richer RDF graph than the previous one. For example, next we describe two filters illustrated in Figure 5.
- Filter of Equivalent Labels.This filter recognizes all concepts that have rdfs:label or foaf:name labels identical to some concepts already registered in the circumstances repository. Hence, the new graph is attached to the existing circumstances graph.
- DBPedia filter.This filter links some concepts of the incoming graph to global concepts of the DBpedia Project introduced in the Related Work section. For instance, if the graph has a concept of type geo:SpatialThing that has a label “Talca”, it is possible to ask the SPARQL Endpoint of DBpedia if there is something of type geo:SpatialThing called “Talca”. In fact, this query would return a resource with URI http://dbpedia.org/resource/Talca. After identifying this fact, the incoming graph is connected to a DBpedia concept. This is an example of how by accessing structured data on the Semantic Web it is possible to integrate local data with a global knowledge of the world.
Note that input from museums and archives repositories enrich or feed an image of the world, maintained both in the circumstances repository and in the global Semantic Web. Once all the filters have been processed, the output of the ingesting process is an RDF graph connected with circumstances stored in CONTEXTA.
All the described processes are automatically done. Obviously, this could generate some relevant semantic problems; for instance:
- If the filter of Equivalent Labels is used, “Margot Loyola P.” would be identified as a different person from “Margot Loyola”
- If the information in an original repository is not complete enough, as is expected, some completely false “facts” could be concluded: e.g. Linares is a city of Chile and also a city of Spain. If input data does not consider the country, then the filtering could result in erroneous conclusions.
These are just two examples of a great number of similar situations that could happen when automating the semantic enrichment process. It would not be appropriate that all of these new possible confusing circumstances be stored immediately in the global repository of circumstances. This is when the pending repository and the auditing process become relevant.
Once the new RDF statements are stored in the pending repository, these statements will not be validated until an expert human auditor approves them. When faced with this situation the auditing component provides capabilities to edit the pending RDF. In future stages of the project we will give Natural Language Processing (NLP) facilities to the auditing component. This way, the human expert will receive valuable help when evaluating statements, suggesting possible errors or redundancies. For instance, a similarity analysis could suggest that “Margot Loyola” and “Margot Loyola R.” could be, in fact, two names for the same person.
Once the data are validated by the auditing component, they become linked to the already stored circumstances. It is at this point that persistent URIs for artifacts, digital representation and circumstances are created. Because we are following the principles of the Linked Data initiative, these new URIs become “dereferenceable”; therefore, they become part of the global Semantic Web.
Another component that is relevant to ingesting and auditing processes is the Expert Feeder. When new data enter the Ingester, these data are enriched thanks to the filters that access extern sites and, mainly, the existing circumstances in the repository. This means that the more circumstances that are stored in the CONTEXTA/SR catalog, the more interesting relationships appear. We called Expert Feeding to the process of populating circumstances directly, without an ingesting process. Generally these circumstances correspond to thesaurus or ontologies instances available on the Web. For instance, the GeoNames service has made available all its RDF geographic data as a downloadable dump (http://download.geonames.org/export/dump/). Also, GeoNames provides an on-line service to access its data on-demand from the Internet. In terms of efficiency, maybe it is a good idea to download the dump and load it into the RDF catalog using the Expert Feeder component.
There is another usual situation when analyzing the domain of a particular institution. Most of the time, cultural institutions have their own thesaurus or ontologies for their very restricted domain. However, this knowledge could be capitalized globally. For example, the MLF has developed a thesaurus of native dialects and languages from South America. This knowledge must be added to the circumstances base. Then if we want to query for music sung in “Mapudungún” (a language of Chilean natives), we will obtain more relevant answers.
Towards an Ecosystem of Applications
CONTEXTA/SR is a platform that provides a set of services acting as semantic middleware for the integration of digital repositories. The architecture is flexible enough to allow the development of interesting applications serving as a core of functionalities.
In particular, the provision of a SPARQL endpoint and dereferenceable URIs at the catalog level allows the development of “semantic mashups”. Semantic mashups are Web applications that use RDF data from several sources and combine the information in useful ways. Figure 6 shows an example of a Web application that was developed using semantic mashups. In particular, the data from CONTEXTA/SR, DBpedia (http://dbpedia.org/), GeoNames (http://www.geonames.org/) and the Google Maps service (http://maps.google.com/) were linked to support an application where the context of the artifacts is explicit. This rich application was developed in a simple way, reusing data and services that already exist.
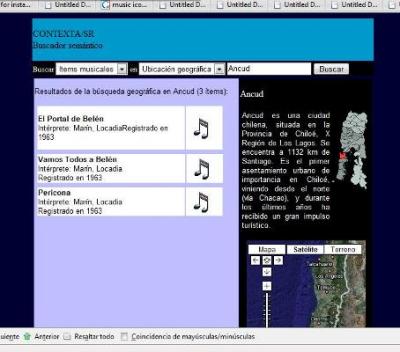
Fig 6: Screenshot of the web application based on semantic mashups
As well as the facilities to make semantic mashups, other Web services are included for common tasks. This has great potential because CONTEXTA/SR’s core has capabilities for high value-adding, such as recommendations, users’ profiling, among others. In a nutshell, CONTEXTA/SR provides a series of capabilities that developers of cultural applications can profit from. There could be a series of applications that “survive” thanks to the provided core, like a software ecosystem.
Discussion and Conclusions
We have presented the initial architecture of the CONTEXTA/SR platform as a solution for integrating distributed and heterogeneous repositories of cultural heritage. At this stage of the project, two archives have been integrated in our framework, acting as a proof of concepts. However, we are conscious of the complexity of the problem we are facing. We have to develop more filters and give more capabilities to the auditing and expert feeder components to prove that this solution work scales with more institutions.
Also, we need to devote part of our efforts to developing rich clients that demonstrate the power of our approach. An ingester client, an expert feeder client and a heritage explorer Web application are in development. Particularly, the explorer Web application will demonstrate the power that the social dimension has in the domain of cultural heritage.
In a nutshell, we have presented a very modular approach to integrate distributed repositories of cultural heritage. The edges of our development have been the extensibility of the platform and the semantic enrichment of the data. The former has been achieved by providing a set of services that any developer can profit from. The latter has been accomplished by clearly defining the ingesting and auditing processes. It is important to stress that although we could have a sophisticated automated process to semantically enrich the data, we still consider that human intervention is absolutely necessary. In our architecture, the Expert Feeder and the Auditor reflect this.
Acknowledgments
Javier Pereira, Victor Codocedo, Marcelo Aliquintuy and Cecilia Astudillo have significantly collaborated in the discussion of the ideas presented in this paper.
References
Auer, S., C. Bizer, J. Lehmann, J. Kobilarov, R. Cyganiak, and Z. Ives (2007). DBpedia: A Nucleus for a Web of Open Data. Proceedings of the 6th International Semantic Web Conference and 2nd Asian Semantic Web Conference (ISWC/ASWC2007), Busan, South Korea, 4825: 715--728, 2007.
Berners-Lee, T., J. Hendler and O. Lassila (2001). The Semantic Web. Scientific American, 284(5), pp. 34-43, May 2001.
Gruber, R. (1993). A translation approach to portable ontologies. Knowledge Acquisition, 5(2):199-220, 1993.
Hyvönen, E., E. Mäkelá, M.Salminen, A. Valo, K. Viljanen, S. Saarela, M. Junnila and S. Kettula (2005). MuseumFinland--Finnish museums on the semantic web. Web Semantics: Science, Services and Agents on the World Wide Web, Vol. 3, No. 2-3. (October 2005), 224-241.
ISAD(G) (2000). ISAD(G) General International Standardization Archival Description, 2nd edition, ISBN 0-9696035-5-X, International Council on Archives, Ottawa 2000.
Junnila M., E. Hyvönen and M. Salminen (2007). Describing and Linking Cultural Semantic Content by Using Situations and Actions. In: K. Robering (Ed.). Information Technology for the Virtual Museum. LIT Verlag, Berlin., Oct, 2007.
Lagoze, C., D.B. Krafft, S. Jesuroga, T. Cornwell, E.J. Cramer, and E. Shin (2005). An information network overlay architecture for the NSDL. Proceedings of the 5th ACM/IEEE-CS Joint Conference on Digital Libraries (Denver, CO, USA, June 07 - 11, 2005). JCDL '05. ACM, New York, NY, 384-384.
Wyman, B., et al. (2006). "Steve.museum: An Ongoing Experiment in Social Tagging, Folksonomy, and Museums," in J. Trant and D. Bearman (eds.). Museums and the Web 2006: Proceedings, Toronto: Archives & Museum Informatics, published March 1, 2006 at http://www.archimuse.com/mw2006/papers/wyman/wyman.html