|
|
Fig. 1 shows this methodology in a more schematic way:
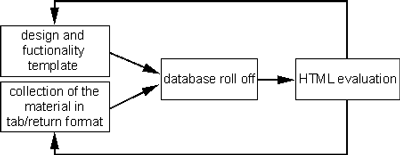 The database roll off program is the kernel of our collection of tools, although other important steps during the course of publishing digital archives are supported as well (see below).
The database roll off program is the kernel of our collection of tools, although other important steps during the course of publishing digital archives are supported as well (see below).
The tools are written in Java, all the intermediate steps and the final data format are completely based on the ASCII standard, so the whole process is totally platform independant.
The Way Things Work
Let us turn to an application of the database roll off tool.
The most simple application of the roll off tool is a 1:1 match of the former database records to HTML documents. Now everything between two returns within the tab/return database export is inserted at the places indicated by the template document.
This is accomplished by using a field wildcard for the HTML document filename. The filename may include the path, this means that hierarchies of directories could be generated right off the database.
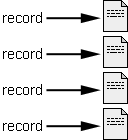
Fig. 2
In terms of ASCII files and HTML templates this looks like the following:
The case opposite to the latter is an n:1 match between data and template. This is especially useful for the generation of lists or tables.
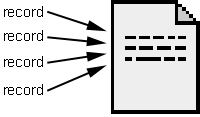
Fig. 3
Again we show this in terms of database export and HTML template:
As always, the most interesting case is a mixture of the „pure" ones above: let's call it the n:m case.
Here, filenames appear redundantly within the sorted database export. Only if a new filename appears, a new file is created by the database roll off tool. Otherwise a loop is being processed within the HTML document. The program suggests possible scopes for the loop, based on the syntax of HTML: only nestable HTML structures, e.g. lists within a document or sequences of coordinates within a clickable map, could be chosen by the user.
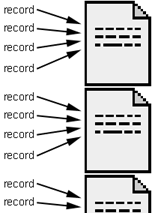
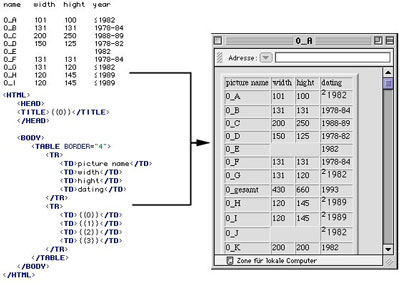
Fig. 4
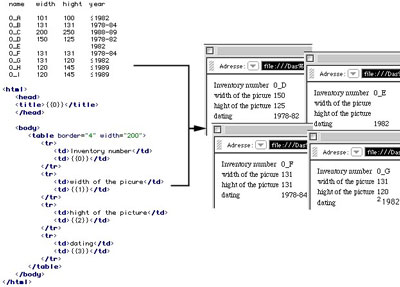
As an example for this an excerpt of the digital archive about the artistic estate mentioned above is shown: HTML pages containing clickable maps:


Terms like "0_A" or "0_B" in the example document are inventory numbers, x1 through y2 indicate the coordinates of the clickable map shapes, here being simple rectangles.
A second example shows the making of different picture catalogues:
fig7.jpg
A special application to the n:m case are index lists, where nested loops appear. The address of an index entry has to be repeated within the list of entries, which is a loop itself. Sometime we would like to have individual files for every letter of the alphabet, which means another repetition.
fig8.jpg
Needles in haystacks and other nuisances
Our collection of publishing tools also contains indexing engines, since -- strangely enough -- the standard HTML editors do not offer this basic and extremely useful philological technique. The main function of this text tool is to generate an index of HTML documents within directories. The result a sorted word list with links to the paragraphs within the documents where the word could be found. Stop words could be indicated for omission from the index, inflection lists are used to trace back the variants of a word to their syntactical roots. Besides this, the tool does some „dirty work" as conversions between ASCII and HTML, splitting up database files into seperate ASCII files and some more useful tasks. It has been used extensively for the diverse indexes of the „Umarmungen" project.
What is the use of all of this?
By use of the tools described above -- in partucular the database roll off tool -- we have been able to generate a highly complex multimedia system like the „Umarmungen" project (a sample could be obtained from the authors) in HTML, consisting of 17500 individual files, from well structured databases on CD ROM without database front end programs. This can be done without any programming skills by just the use of any database, an HTML template file generated by hand or with an HTML editor, and the tools we built that run in any Java virtual machine environment.
This proved that HTML is an appropriate format for sustainable multimedia projects whithin the field of scholarly work, even for those not willing to program themselves or to restrict the structure of the documents to a rigid database format.
Researchers interested in these tools may obtain them without fee for their own non profit purposes. Please contact the authors if you should be interested in using them.
Reference
The former proprietary HyperCard version was demonstrated during the ICHIM '95 conference in San Diego (Wedemeyer, C, and Warnke, M.: Documentation and Edition of the Artistic Estate of Anna Oppermann with Computer Aided Methods - the Prototype for the Ensemble „Umarmungen, Unerklärliches und eine Gedichtzeile von R.M.R." („Embraces, Inexplicables, and a Line from R.M.R.")) and is now available as HTML version in „Wedemeyer, C. (1998). Umarmungen…/Embraces - Anna Oppermann's Ensemble "Umarmungen, Unerklärliches und eine Gedichtzeile von R.M.R.". Ein hypermediales Bild-Text-Archiv zu Ensemble und Werk/A hypermedia picture text archive on ensemble and work. In Englich and in German language. Frankfurt/Main, Basel, Stroemfeld Verlag. The CD-ROM contained in the book could be obtained for free by sending an email to warnke@uni-lueneburg.de.
A description of the project and the hypermedia catalogue of the works and of all texts of Anna Oppermann can be found under http://www.uni-lueneburg.de/BildTextVideoarchive
|

