|
|
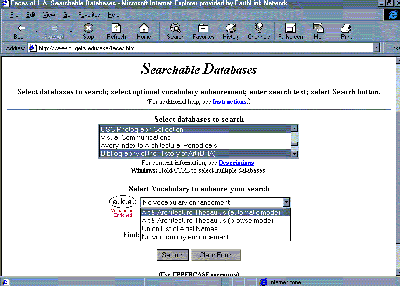
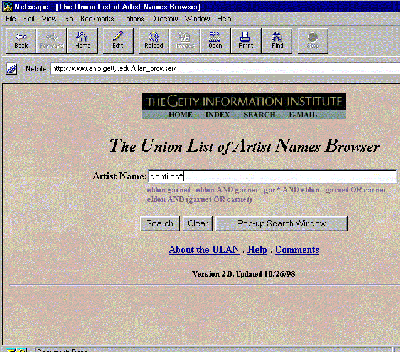
| Figure 9: Screen from an early version of "a.k.a." (this version is no longer supported). User was provided with pull-down menus to choose 1) which databases to query and 2) which vocabulary (if any) to use to enhance the search. |
When vocabularies are employed in an automatic way, issues include how many related terms to include in the query. Should only synonyms and language equivalents be included? Should "see also" references be included? Should narrower hierarchical concepts be included? While all of these related terms could potentially be useful when applied in a query, there is the danger that too many terms will be employed and thus make the search too time-consuming and the result set too large. In order to maintain acceptable retrieval speed, compromises were made as appropriate to the characteristics of each vocabulary's content: The AAT synonyms and related terms were included, but the "children" were not; the ULAN "project-preferred" synonyms were included, but the full list of variant names was not.
Many commercial Web browsers that use thesauri do so transparently, broadening searches without interaction by the user. While the interface may thus be simple and easy to use, the disadvantage, of course, is that the end-user is denied control of the search criteria. More accurate results are achieved in "a.k.a." when the user hand-picks which vocabulary terms to incorporate in the search.
The advantage is illustrated in the latest version of "a.k.a." In order to make the vocabulary component of the search easier for users, this new version includes fewer screens and easier instructions. Access to all three vocabularies is available on the same screen, whereas in the older version the user was taken to separate screens for each vocabulary.
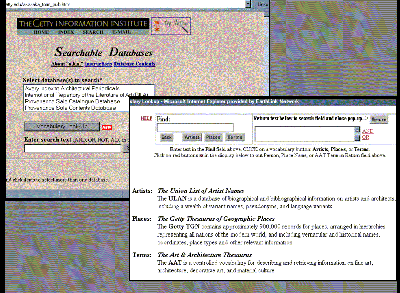
| Figure 10: "a.k.a." http://www.gii.getty.edu/aka (accessed January 15, 1999), revised implementation. User is asked to choose which databases to query, and may go to a vocabulary window. |
The application of vocabularies is also more powerful in the newer version of "a.k.a." because the user can link terms from multiple vocabularies with Boolean operators, whereas in the earlier version the user could query with only one vocabulary at a time. Therefore, for example, a user interested in finding a particular type of ancient Egyptian funerary sculpture that is in Cairo can now combine synonyms for "Cairo" from the TGN with synonyms for "ushabti" from the AAT in this statement: ("Al-Qahirah" OR "El Q�hira" OR "Cairo" OR "Le Caire" OR "Kairo") AND ("ushabti" OR "shabti" OR "shawabti" OR "ushabtis" OR "ushabtiu"). Then these terms may be used to query across various databases.
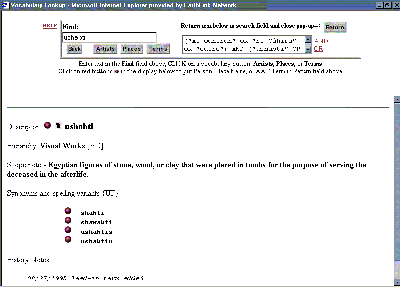
| Figure 11: "a.k.a.", vocabulary screen. User is able to pick multiple terms from multiple vocabularies, linked by Boolean operators, and apply these terms to a query across several databases. |
Continuing Problems with Retrieval. The outstanding issue that plagues the new "a.k.a." implementation is the same one that affects most searches on the Web: No matter how skillfully terms are gathered, when they are then used to retrieve indiscriminately from texts, results may be unexpected. For the query above, one could retrieve a "ushabti" in Boston because there is a mummy case from Cairo on the same Web page. Often the results are even more disappointing: for example, the word "painter" is part of many terms in all three vocabularies - an occupation can be "painter" in the AAT, an artist's name can be "Painter" in the ULAN, and towns in TGN may be named "Painter." If one searches using that term on a general Web browser, more than 500,000 pages are retrieved, and many have nothing to do with fine art; they include pages for a realtor named "Painter," discussions of environmental problems on Mount Painter, and advertisements for clip art in a product called "Painter."
The most obvious way to improve results is to use the vocabulary terms to search across databases, but limit the search to a single, common field in all the databases. This approach could be used in local or controlled environments, such as at the Canadian Heritage Information Network (CHIN) , where object records from disparate databases are gathered and mapped to a common format. In a situation like this, where each museum may have existing, established standards and conventions, using the AAT - in the case of CHIN, supplemented with French-language equivalents - to help gain access to the material is clearly advantageous. Furthermore, if the data is in a controlled environment and fielded, more accurate results could be ensured by performing queries only on particular fields (e.g., querying on "painter" could be restricted to an artists' role field). In addition, results could be gathered across all fields, but sorted by individual or related fields (e.g., as at CHIN, where they are grouped under user-friendly labels such as "What, Who, When, Where, How").
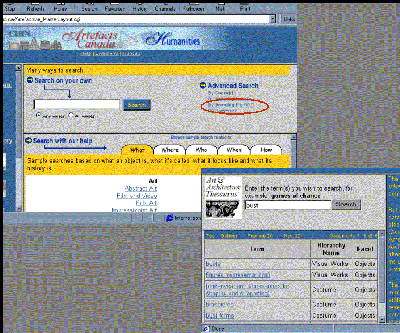
| Figure 12: Canadian Heritage Information Network (http://www.chin.gc.ca/Site_Index/e_site_index.html, accessed January 15, 1999). Users may consult the AAT to gather terms, which are then applied across several CHIN data sets, and the results are grouped into meaningful sets based upon the data field in which the terms were found. |
Directing queries at specific information is, of course, more difficult when the data is not fielded. If more Web pages were tagged with metadata in meaningful ways, this could begin to allow queries to be more focused, even in an open environment. Many museums are beginning to experiment with Dublin Core; these metadata tags could allow vocabulary terms to be targeted at particular areas of a Web document. For example, the Dublin Core was recently used to index a "virtual" exhibition at the Getty, and plans are being developed to employ the Dublin Core in other online resources throughout the programs of the J. Paul Getty Trust.
In addition to enhancing access across disparate databases, the Getty vocabularies have also been helpful in providing access to information in narrowly focused databases, as in the interface to the Census of Antique Art and Architecture Known to the Renaissance. However, an issue arises in such implementations that is similar to one found in implementations for collection management systems: Much of the terminology in the vocabulary may be outside the scope of the database, and thus the terms would retrieve nothing. For example, since the Census database has a prescribed focus of art and architecture from classical antiquity and the Renaissance, and since terminology was controlled at the stage of data entry, a list of keywords is not too large to be overwhelming to the user who wishes to browse through it. Another way of dealing with this issue would be to limit queries on the AAT to only relevant hierarchies, or to link the Census keyword concepts to corresponding AAT records.
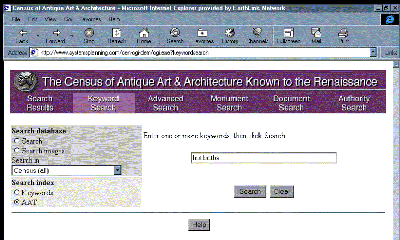
| Figure 13: Census of Antique Art and Architecture Known to the Renaissance interface, designed by Systems Planning (the Census database is only available online to authorized users; however, a demonstration of the interface is available at http://www.systemsplanning.com, accessed January 15, 1999). The interface allows users to query the AAT for terminology or to pick from a list of keywords gathered from the Census data. |
A vocabulary can be useful in a narrowly focused database by retrieving concepts based on information other than the term itself. For example, in the Census implementation (which uses the vocabulary component developed for "a.k.a.") the user may search the AAT scope notes as well as the terms themselves. For example, if a user wants to find information on Roman hot baths but does not know the correct term, he can enter "hot bath" and retrieve "caldaria" (and variants "caldarium," "calidaria," and "calidarium") because the scope note contains the keywords "hot AND baths" ("The vapor baths or hot plunges in Roman baths"); the appropriate terms can then be passed to the Census interface and used to search the database for records containing these criteria: "caldaria" OR "caldarium" OR "calidaria" OR "calidarium."
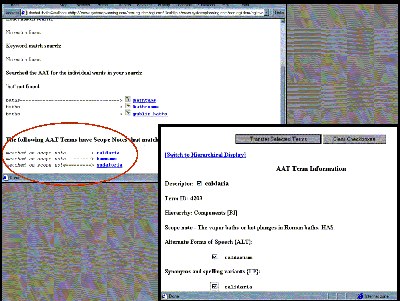
| Figure 14: The AAT as accessed from the Census interface. User may search AAT scope notes for "hot AND bath" and choose appropriate terms for querying the Census data, e.g., synonyms and variant parts of speech: "caldaria," "caldarium," "calidaria," and "calidarium." |
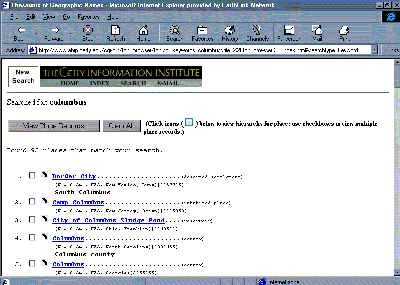
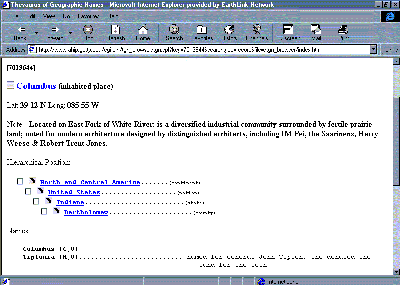
In addition to all the issues discussed above, a number of other problems can surround an implementation of vocabularies on the Web. Among these is the fact that terms are less meaningful when taken out of context. For example, there are many homonyms in geographic information; thus, querying on a common name from TGN, such as "Paris," may retrieve too many results. If there were a way to add the broader context to the query, this could narrow the results (e.g., for example, adding one or more of the "parents" of Paris, which are Europe, France, and �le-de-France). However, even though TGN will supply the names of the parents of Paris, these parents' names are probably not included in the databases targeted for the query. Likewise, ULAN or AAT terms taken out of context can retrieve incorrect results. For example, in AAT, "Edo" is the name both of an African style and a Japanese style; "stretcher" is a furniture component, a masonry unit, and equipment for mounting and framing; these terms exist as separate concepts in different parts of the AAT hierarchies. In a local or controlled environment, the unique numeric identifier for a concept could provide a link between the material being queried and the vocabulary used to aid retrieval (for example, the seven-digit number 7008038 is the unique identifier of Paris, France in TGN). For instance, the identifier could be placed in the object record by a cataloger, and could thus be linked to the vocabulary and provide extremely accurate retrieval.
Further potential issues with using the vocabularies in implementations can arise from the forms of the terms themselves. All of the usual problems that can apply to retrieval by words generally can apply here, such as failure to retrieve based on differences in case, punctuation, diacritics, etc. These issues are overcome in the Getty vocabulary browsers by creating normalized strings for retrieval (e.g., all names are translated into lower case, and spaces, punctuation and diacritics are removed). Other issues are more unique to the vocabularies themselves. For example, the homographs in AAT are distinguished from each other by parenthetical qualifiers, such as "drum (column component)" and "drum (membranophone)." If these terms are taken verbatim and applied in a broad query on the Web, the results will be limited, because relatively few resources will include both "drum" and "membranophone" on a page discussing drums, and none is likely to have the exact term "drum (membranophone)," parentheses and all. Also, in TGN and ULAN names may be recorded in inverted order, but the resources being queried may list the name in natural order. For example, in ULAN the eighteenth-century architect's name is recorded as "Wren, Christopher" and "Wren, Sir Christopher"; however, a museum Web page is likely to list him as "Christopher Wren." A retrieval interface can start to solve this by looking for keywords "Wren AND Christopher" on the same page. However, one would also retrieve a page about non-native common wrens, Troglodites parvulus, on the islands of St. Christopher-Nevis. In order to avoid the kind of imprecise retrieval that may result from that method, another solution has been applied to the ULAN: In the ULAN browser, algorithms were applied to parse the ULAN artists names and globally create a new set of variant names in natural order, to be used for retrieval.
Conclusion
Although many issues must be considered in order to successfully integrate vocabularies in Web searching assistants and other implementations, vocabularies provide the terminology and hierarchical structures to allow users to retrieve information across disparate databases and in various languages. The Getty vocabularies can provide critical variant names and thesaural relationships that allow improved retrieval of art and cultural heritage information. It is clear that vocabularies are the key to navigating and retrieving meaningful results from the massive amount of largely inchoate information now potentially available in digital form.
|