Introduction: The Complexities of Sharing Research and Collections
Open Context (http://www.opencontext.org), is an online, open access publishing system, developed to support enhanced scholarly communication in archaeology and related disciplines. It was developed by the Alexandria Archive Institute (http://www.alexandriaarchive.org) with a series of grants from the William and Flora Hewlett Foundation (http://www.hewlett.org) as a collaborative approach to sharing and integrating field research and museum collections. Individual researchers, small project teams, museums and other organizations often maintain rich, varied, and growing digital collections of cultural heritage. Many such collections are organized in highly structured databases. However, most open source solutions for Web-dissemination best support less structured narrative media. Thus far, structured databases typically demand expensive, customized solutions for Web dissemination. Furthermore, the diversity of recording systems, data structures and database designs typical of the humanities and social sciences mean that Web dissemination solutions developed for one collection do little to make other collections accessible. These costs inhibit small institutions, individual researchers or small research teams, and organizations in the Developing World, from sharing rich collections of cultural heritage on the Internet.
Technical Challenges to Data Sharing
One of the greatest hurdles to sharing data online is the great diversity of content generated in most disciplines. Databases tend to be project-specific, posing a challenge to data sharing, even within a narrow field. Large project databases often include tens of thousands of individual records created by multidisciplinary teams, all in complex relationships. If a dataset needs to be downloaded and deployed on specific software, it may be difficult to use even with adequate documentation. Once deployed, users will have to familiarize themselves with a project’s database organization and interface. The steps involved in downloading and deploying such databases require too much time and expertise for the average user.
To attract and keep users, Internet-based data sharing systems should be designed so that they appear immediately familiar and accessible to first-time users. They should be easy to navigate and not require any additional steps for use (such as downloading plug-ins or creating password-protected accounts). They should also provide apparent and immediate rewards for data contributors, such as clear attribution of authorship, editing functions, and search engine exposure. Many well-funded projects have custom designed Web sites that provide access to all or part of their research. However, customization and database design are time-consuming and costly. A generalized solution for sharing and exploring data across multiple projects would be much more effective than customized, project-specific systems.
Even if data sharing systems are simple to use, many researchers are reluctant to publish data that they perceive as too small, too incomplete, or too “messy” to share with the world. Smaller projects, in particular, suffer from information loss because they have little capacity to develop customized solutions on their own. They may generate rich bodies of documentation, but without Internet dissemination, much of this material will never see publication because paper simply isn’t up to the task. Data sharing systems must be flexible to accommodate all content generated in projects large and small, complete and incomplete.
Scholars sharing their research via the Internet need assurance that it will be preserved in its original form. Too much research is vulnerable to loss through accidents or neglect. Researchers need easy tools to publish their digital materials in open file formats (that can be read by free software and are more likely to stand the test of time). They also need help migrating their materials to digital archives. Thus, open content systems should include simple migration and archiving options.
Cultural Barriers to Data Sharing
In our experience creating Open Context, the most frequently voiced concerns over data sharing are the perceived loss of professionalism (peer review) and authorship. However, “going online” does not require abandoning peer-review and adopting the radical egalitarianism of the Wikipedia. Peer review can be built into open digital dissemination and is already successfully in place in many open access journals (Harnad and Brody 2004).
Professionalism also requires proper attribution of an author’s work and many scholars worry that open access will cause their content to be “scooped” by someone else. Clear and recognized forms of citation will make researchers more comfortable with online data publication. Systems should have clearly marked authorship and citation information for every piece of content they contain (Kansa 2007). Other features such as timestamps on contributions, logos, and search engine indexing, make original contributors easy to recognize and provide exposure that would deter misuse.
Open Context: A Flexible, Community-Based Data Publication Solution
With the above challenges in mind, the Alexandria Archive Institute developed Open Context, an open access data sharing system developed to support enhanced scholarly communication in archaeology and related disciplines. We determined that the most important requirements for this system to see widespread community adoption were the following:
- It is easy to navigate for the “average” computer-literate user
- It accommodates diverse and non-standardized projects
- It is scalable (that is, generalized to apply to many different projects without requiring expensive customization)
- It is academically robust (peer-reviewed and citable)
Open Context enables researchers to publish structured data along with textual narratives and media (images, maps, drawings, videos) on the Web. This new system provides a cost-effective and scalable solution to the current problems of data loss and limitations to data sharing. Given the diversity of cultural heritage content and the limited financial resources of many organizations in the cultural heritage sector, cost-effective dissemination solutions based on common services and tools are required. The system provides a Web-based tool for researchers and collections managers to upload, “markup” and publish diverse archaeological and museum collection datasets. Once published, users can browse, search, query, and analyze multiple field project and collection datasets (see Figures 1 and 2).
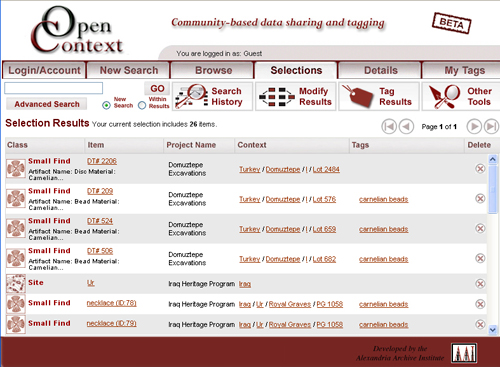
Figure
1: Results of a search for “carnelian”,
showing items from multiple projects

Figure 2: An image linked with its registry record and
context
Open Context implements the highly generalized ArchaeoML schema (advanced by the University of Chicago OCHRE project) in a simple MySQL/PHP driven system. This schema enables Open Context to dynamically manage multiple datasets that do not conform to any predetermined standard recording systems, database organization or vocabularies. Important features include:
- Web-Based Data Publication: Open Context provides a Web-based publishing tool (“Penelope”) that enables individuals to publish their own datasets and make them interoperable with other projects and collections in Open Context (see Figure 3).
- Data to Knowledge: By offering comprehensive access to highly structured excavations and collections data, Open Context also supports reanalysis and reinterpretation of excavation results. Students can use Open Context as a “primary source” to develop important analytical skills by exploring primary excavation results.
- Citation and Easy Retrieval: Stable URL links are attached to each and every piece of content, so items can be referenced in paper or e-publications and retrieved on the Web. Automatic generation of citations for each item enables scholarly use (see Figure 4).
- Community Approach to “Data Integration”: Open Context operates on a “folksonomy” system to help the user community link and annotate selected sets of items from different projects and collections, incrementally working toward semantic data integration. Users can tag items either individually or collectively (i.e. users can assign a tag to items in a query result set). When query result sets are tagged, the history of query composition is automatically linked to the tagging event. Users can further annotate and explain the rationale behind their tag assignments. Tags can be used to save search selections for future reference and to share sets of items with colleagues.
- Community-Enriched Content: Open Context provides feedback tools, such as a “ping-back”, which keeps track of external links to the data in the system. If someone uses a Weblog to discuss a collection, they can link to an item or set of items in Open Context. Open Context would recognize that link and send an email to a museum administrator to make sure that the Weblog post makes appropriate use of the data. If the administrator agrees, Open Context will automatically make a link back to it to the referring Weblog. This is a way of adding value to collections data, since the database can carry links to relevant interpretations, commentary, and analyses.
- Data Visualization and Export: Open Context provides data analysis tools, including easy export to MS-Excel and statistical summary and charting tools.
- Sharing Updates: Open Context broadcasts a number of RSS feeds (specifically, RSS 1.0 and RSS 2.0). RSS (“Really Simple Syndication”) is a widely adopted Internet standard for sharing updates of content between different Web services. Open Context RSS feeds enable content contributors to share news and updates across the Internet.
- Dublin Core Metadata: Open Context uses Dublin Core metadata to meet the Open Archives Initiative Protocol for Metadata Harvesting. Dublin Core metadata are expressed in the COinS microformat, which facilitates citation (especially with the new Zotero bibliographic tool).
- Impact Measures: Assessing the value of primary data publication is still in its infancy (Piwowar, Day & Fridsma 2007). Nevertheless, recent studies have shown a significant correlation between download counts and more traditional citation impact measures (Brody, Harnad & Carr 2006). In order to take a preliminary measure of the usage and significance of each dataset, Open Context records information on visits and publicly displays running summaries of these usage data.
- Longevity Support: The Internet Archive and the University of Chicago OCHRE Project provide long-term archiving of all the digital content in Open Context.
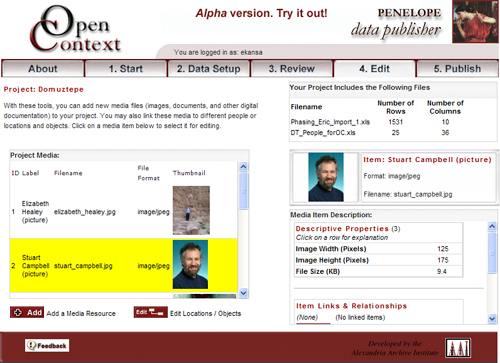
Figure
3: A view of Penelope, Open Context’s Web
application for data publication
 Figure
4: An automatically-generated citation for an Open Context item
Figure
4: An automatically-generated citation for an Open Context item
Removing Barriers to Sharing
Open Context represents an attempt to build cost-effective tools to link field research and museum collections with active discussions and creative reuses, making these collections a much richer and integral part of continued cultural and scholarly production. All content in Open Context is “open access”. This means that the contributor agrees to make it available on the Web, free of charge, for others to explore and reuse. Open Context is unique in that it provides a framework for sharing cultural heritage research while making authorship and usage permissions clearly expressed and embedded within the system, thus meeting the needs of both content providers and users. Each item in Open Context is licensed with a Creative Commons license that gives explicit permissions to copy and use material so long as they properly attribute the source and abide by certain optional conditions. Creative Commons licenses (http://creativecommons.org) now see wide implementation in many leading scholarly Web resources. The prestigious journals published by the Public Library of Science (with impact factors rivaling Nature, Science, and Cell) use Creative Commons licenses to clarify terms and permissions for each of their scientific articles. This openness and flexibility ensures that Open Context content is of maximum value for reuse in both instructional and research applications.
Acknowledgements
The authors would like to thank those who have participated in making Open Context operational, especially David Schloen and the University of Chicago OCHRE project for their continued support and partnership. Thanks also to Ahrash Bissell for his continued insights and ideas in applying Open Context to the biological sciences and education. Needless to say, any omissions or errors in this work are solely the fault and responsibility of the authors. Finally, Open Context and many other open education initiatives directly result from the enabling financial support of the William and Flora Hewlett Foundation. Their support, together with the generous financial contributions of Doris and Donald Fisher and the Joukowsky Family Foundation, help ensure that Open Context can serve as a free and open access resource for the community.
References
Brody, T. S. Harnad and L. Carr (2006). Earlier Web Usage Statistics as Predictors of Later Citation Impact, Journal of the American Society for Information Science and Technology 57(8):1060–1072.
Harnad, S. and T. Brody (2004). Comparing the Impact of Open Access (OA) vs. Non-OA Articles in the Same Journals, D-Lib Magazine 10(6). http://dlib.org/dlib/june04/harnad/06harnad.html Accessed July 6, 2007.
Kansa, E. (2007). Publishing Primary Data on the World Wide Web: Opencontext.org and an Open Future for the Past. Society for Historical Archaeology, Technical Briefs http://www.sha.org/publications /technical_briefs/volume02/article01.htm Accessed July 26, 2007.
Piwowar, Day & Fridsma 2007. HA Piwowar, RS Day and DB Fridsma, “Sharing Detailed Research Data Is Associated with Increased Citation Rate”, PLoS ONE 2(3): e308. doi:10.1371/journal.pone.0000308. http://precedings.nature.com/documents/361/ version/1/files/npre2007361-1.pdf
Cite as:
Kansa, E., and S. Whitcher Kansa, Open Context: Collaborative Data Publication to Bridge Field Research and Museum Collections , in International Cultural Heritage Informatics Meeting (ICHIM07): Proceedings, J. Trant and D. Bearman (eds). Toronto: Archives & Museum Informatics. 2007. Published October 24, 2007 at http://www.archimuse.com/ichim07/papers/kansa/kansa.html